贪心算法续
决策树
什么是决策树
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶节点。内部结点表示一个特征或属性,叶节点表示一个类。
决策树学习算法的特点
- 最大优点:自学习。在学习的过程中,不需要使用者了解过多背景知识,只需要对训练实例进行较好的标注,就能够进行学习。
- 从一类无序、无规则的事物(概念)中推理出决策树所表示的分类规则。
- 它属于有监督学习。
决策树的主要算法
建立决策树的关键,是在当前状态下选择哪个属性作为分类依据。
根据不同的目标函数,主要有以下三种决策树算法:
- ID3(J. Ross Quinlan-1975),核心为
信息熵 - C4.5(ID3的改进),核心为
信息增益比 - CART(Breiman-1984),核心为
基尼系数
主要步骤
将特征空间划分为互不相交的单元或区域,并在每个单元定义一个类的概率分布,这就构成了一个条件概率分布。
各个叶结点(单元)上的条件概率往往偏向某一个类,即属于某一类的概率较大,决策树算法在分类时将该结点的实例(样本?)强行分到条件概率大的那一类去。
本质上就是从训练数据集中归纳出一组分类规则。
- 从根节点开始递归生成树,根节点对应整个训练集的样本。
- 对于每一个节点对应的数据集合,算法需要选择出其中的某个特征,使得以该特征进行数据的划分能够使划分效果(相当于区分度)达到最优,然后将其划分为子节点进行递归地划分。
- 直到到达某个子结点无法再进行有效的划分(例如最优的信息增益小于阈值?),则将该节点作为最终的决策结果,生成叶子结点。
基本概念以及特征选择方法
熵
熵在信息论中,是接收的每条消息中包含的信息的平均量,换句话说,如果某个不容易发生的事情发生了,会告诉我们一些特别的信息。
熵表示随机变量不确定性的度量。熵越大,随机变量的不确定性就越大(例如完美抛硬币的熵为1)
熵的计算方法如下:
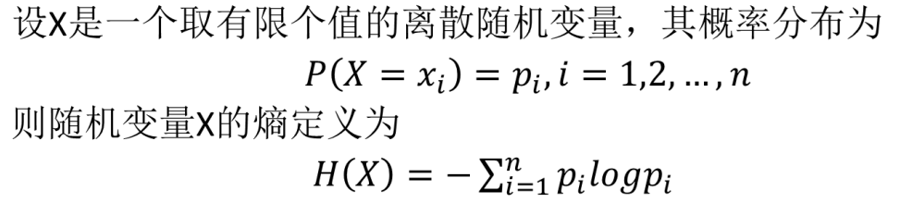
就分类而言,如果所有的成员都属于一类,熵为0;
不同类别的成员数目相等(例如完美抛硬币),则熵为1;
否则如果类别数目不相等,则熵介于0和1之间。

显然,当p=0或p=1时,H§=0,随机变量完全没有不确定性。
条件熵

信息增益
信息增益表示:得知特征x的信息而使得类Y的信息不确定性减少的程度(也就是熵减的量)。
信息增益:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(DIA)之差,即g(D,A) = H(D) - H(D|A)
关注到决策树:
很显然,如果决策树的某个节点对当前的数据集以某个特征Ai做出了正确的决策(或者理解为分类,划分),必定能够让两个集合的区分度更大,每个集合中的数据的特征更加统一整齐。这样就相当于从原本混乱的数据集中划分出了2个相对整齐的子集,熵自然减小。(例如原本的数据集合是蓝色和红色小球混合,两个子集就是所有的蓝色小球和所有的红色小球,混乱度大大降低,本例中降为0?)
当然,一个数据集中不止一个特征A,因此要对于每一个特征Ai都计算信息增益gi,选择出最大的那一个,以此作为最优的划分。这就是根据信息增益准则的特征选择方法。
ID3算法使用信息增益。
具体公式:


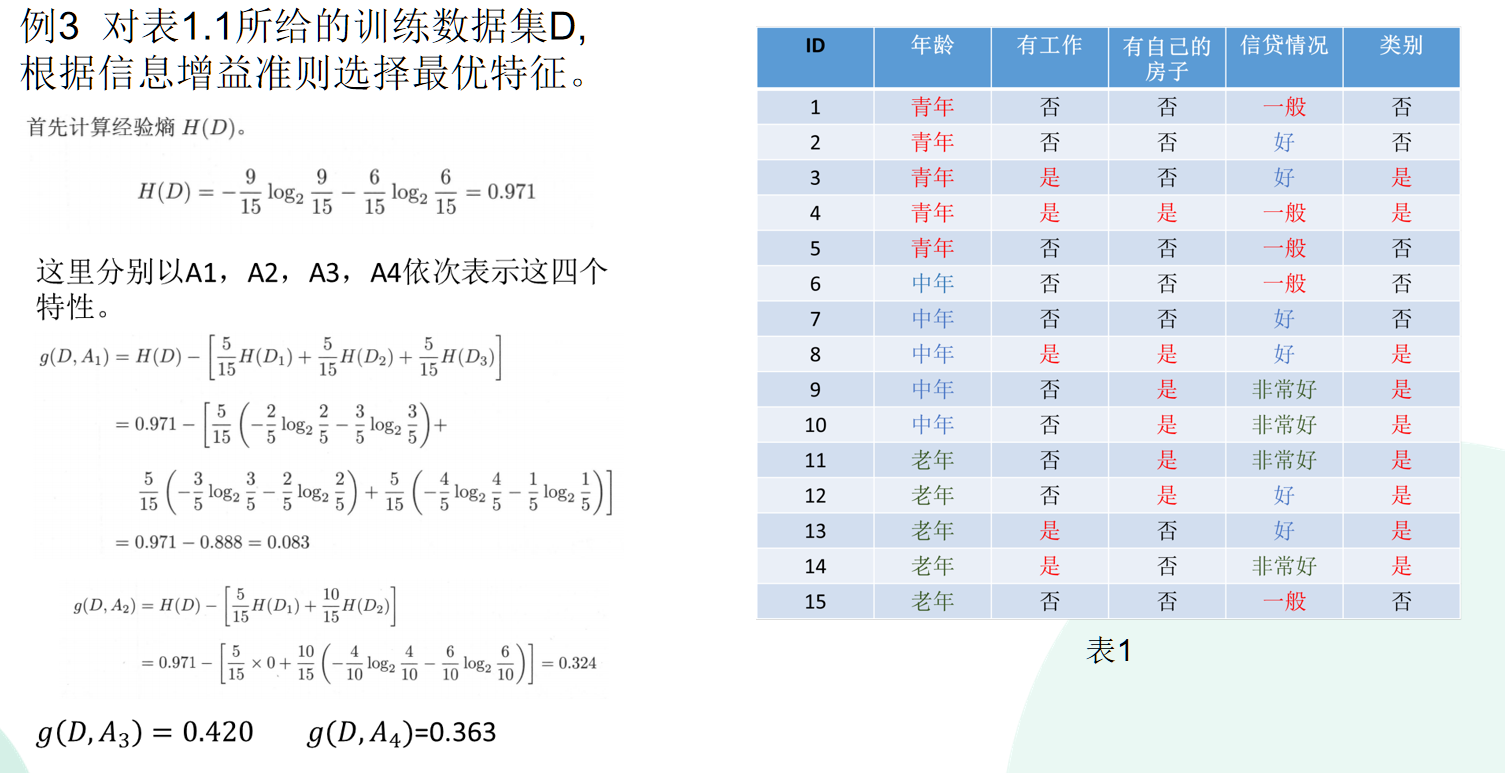
举个栗子:
根据信息增益准则的特征选择方法的问题:偏向于选择取值较多的特征,从而导致过拟合(应该是?)。
使用信息增益比可以很大程度上解决这个问题。
信息增益比

C4.5算法使用信息增益比。
决策树基本流程

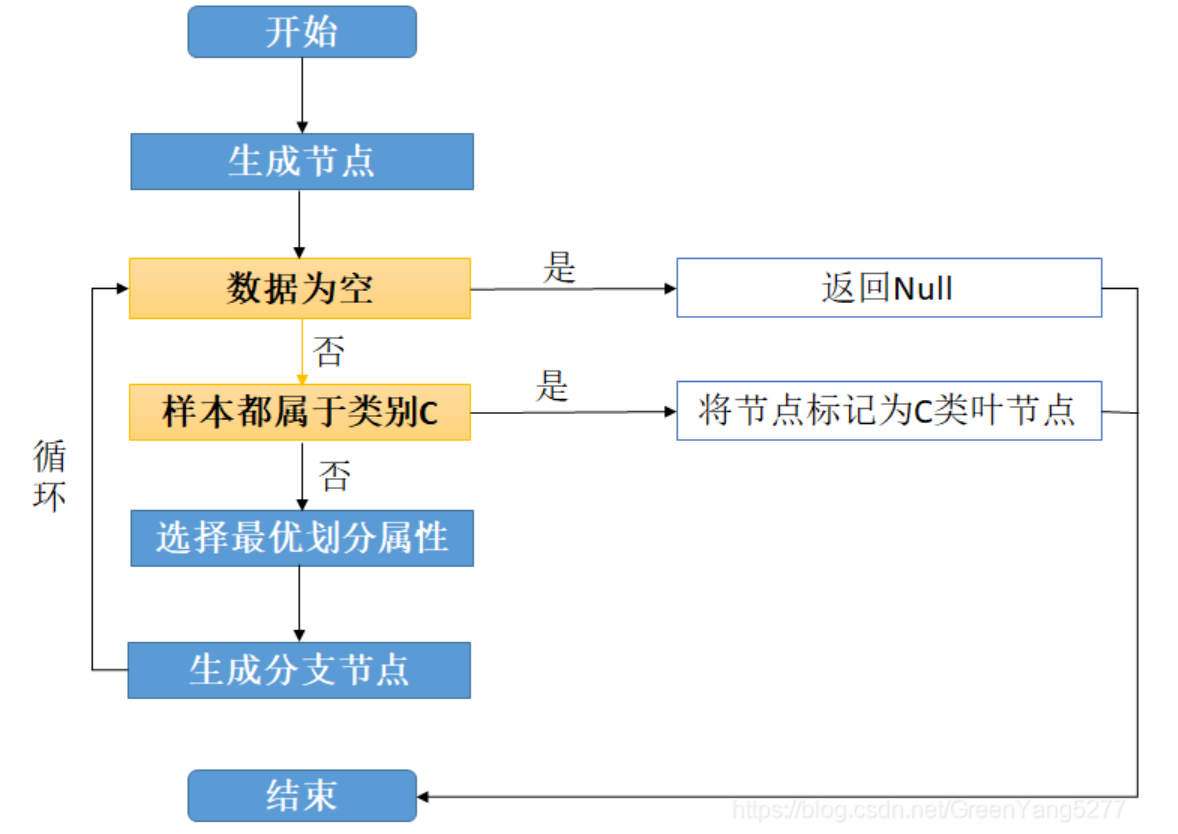
具体的ID3和C4.5算法,这里略,容易找到相关资料。
随机梯度下降
略。。。
注:本文参考自课程ppt
 wechat
wechat alipay
alipay