概述
回溯算法属于暴力搜索法的一种,它是一种可以找到所有(或一部分)解的一般性算法。尤其适用于约束满足问题,在搜索过程中逐步构造候选解,并在确定某一些候选解不可能正确时放弃继续搜索,转而继续搜索并构造其他候选解。
八皇后问题就是一个经典的可以使用回溯法的例子。在使用回溯法解决八皇后问题时,每一步都尝试选择某一行的皇后,在到达某一行后发现无法再继续构造下去,就会直接放弃,进行回溯,继续从上层选择其他的决策,尝试构造其他的摆放方式。在选择出一个完整解后(搜索到最底层行),将其放入答案序列,然后结束算法,或者继续回溯,尝试找到其他可行解。
示例
找出二叉树的所有值为7的节点,返回节点列表
题目:找出二叉树的所有值为7的节点,并返回节点列表
深搜遍历即可,略。。。
在二叉树中搜索所有值为7的节点,返回根节点到这些节点的路径
同样深搜即可,并将路径上的结点压栈,找到结点后将栈作为路径序列返回即可。
在二叉树中搜索所有值为7的节点,返回根节点到这些节点的路径,并要求路径中不包含值为 3 的节点
同样深搜即可,并将路径上的结点压栈,如果遇到值为3的结点则提前返回(剪枝),舍弃之后的路径,在找到值为7的结点后将栈作为路径序列返回即可。
回溯法主体框架

回溯法的优点与局限
本质上是一种深度优先搜索算法,它尝试所有可能的解决方案直到找到满足条件的解
优点:
- 能够找到所有可能的解决方案
- 在合理的剪枝操作下,具有很高的效率
缺点:
- 处理大规模或者复杂问题时,回溯算法的运行效率可能难以接受:
- 回溯算法通常需要遍历状态空间的所有可能,时间复杂度可以达到指数阶或阶乘阶
- 在递归调用中需要保存当前的状态,当深度很大时,空间需求可能会变得很大
优化方式:
- 剪枝:避免搜索那些肯定不会产生解的路径,从而节省时间和空间
- 启发式搜索:在搜索过程中引入一些策略或者估计值,从而优先搜索最有可能产生有效解的路径
经典例题


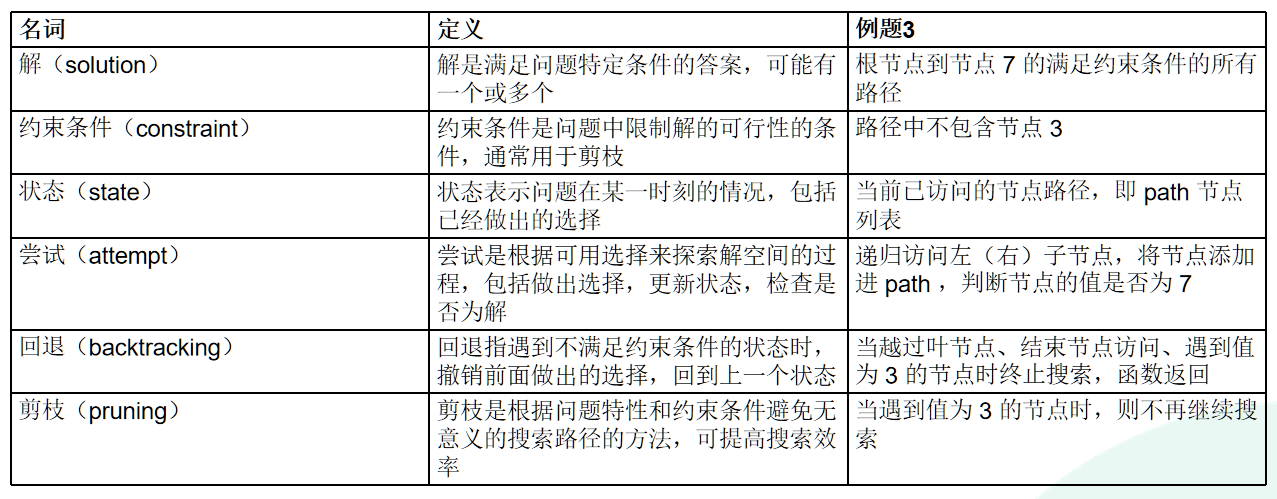
全排列问题
题目:在给定一个集合(如一个数组或字符串)的情况下,找出其中元素的所有可能的排列。
无相等元素的情况
输入一个整数数组,其中不包含重复元素,返回所有可能的排列
使用一个标记数组(或者哈希表)select来让每一个元素只被选择一次,每一层都进行数组的迭代即可
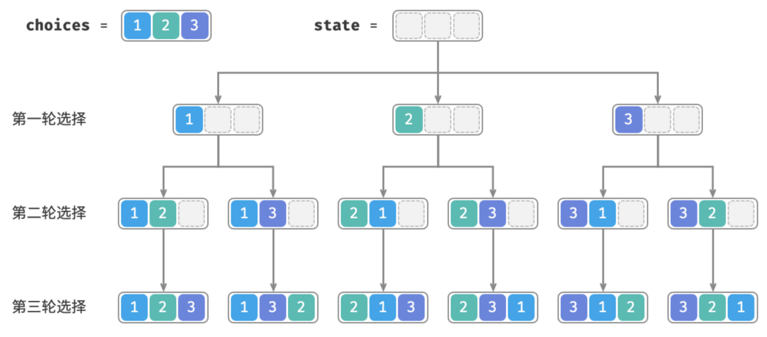

有相等元素的情况
输入一个整数数组,数组中可能包含重复元素,返回所有不重复的排列
最直接的解决办法是引入一个哈希表,直接对结果进行去重,但是并没有对搜索过程进行优化,需要考虑其他方法进行剪枝。
解决办法是,在每一层都引入一个哈希表duplicated,对数组中的每种相同值的元素(而不是每一个元素)做映射,相同值的元素根据该哈希表,在当前层只会有其中一个被选择,这样就避免了重复,代码如下:

额外:Go代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| package main
import (
"fmt")
func permuteUnique(nums []int) [][]int {
var result [][]int
var temp []int
var visit = make(map[int]bool)
var backtrack func(int)
backtrack = func(start int) {
if start == len(nums) {
result = append(result, append([]int(nil), temp...))
return
}
used := make(map[int]bool)
for i := 0; i < len(nums); i++ {
if _, ok := visit[i]; ok {
continue
}
if _, ok := used[nums[i]]; ok {
continue
}
used[nums[i]] = true
visit[i] = true
temp = append(temp, nums[i])
backtrack(start + 1)
temp = temp[:len(temp)-1]
delete(visit, i)
}
}
backtrack(0)
return result
}
func main() {
nums := []int{1, 1, 2}
permutations := permuteUnique(nums)
for _, perm := range permutations {
fmt.Println(perm)
}
}
|
回顾一下,两个哈希表(标记数组也被理解成哈希表也没什么问题,键为下标,值为bool值)select和duplicated的区别:
- select用于记录在当前状态的整个搜索过程所选择的元素下标不会重复,具有一定的全局性,即每一轮选择之间是共享同一个select
- 而duplicated则是每轮(每层)选择中独有的,目的是解决当前轮次重复值元素的选择问题
子集和问题
无重复元素,可以选择多次
问题:给定一个正整数数组 nums 和一个目标正整数 target ,请找出所有可能的组合,使得组合中的元素和等于 target 。给定数组无重复元素,每个元素可以被选取多次。请以列表形式返回这些组合,列表中不应包含重复组合
参考全排列,把子集的生成过程看做一系列选择的结果,并且在选择过程中实时更新元素和,当元素和等于 target 时就将子集记录至结果列表。
需要注意的是,本问题中每个元素可以无限次选取,因此无需使用 select 数组进行标记。
另一方面,由于给定的数组 nums 中的元素均为正整数,因此如果找到了一个合适的解,直接回溯即可,因为继续累加是没有意义的。
进一步,如果直接修改全排列问题的代码,会出现重复的问题,因为结果子集各元素是不关心顺序的,因此会出现 [4,5]和[5,4]这样的重复结果。
当然,可以在最后去重,但是效率极低:
- 数组元素较多时,特别是在 target 很大时,重复子集的数量会非常大
- 去重时,需要排序,然后逐个比较,效率低下
为了更高效地去重,尝试在搜索过程中进行剪枝。很容易发现,重复子集是由于子集中各个元素在原数组的下标顺序并不是严格递增的,例如如果有原数组 [3,4,5],那么应该是 idx[3]<idx[4]<idx[5],因此 [4,5] 满足条件;而 [5,4] 则不满足,将其剪枝:
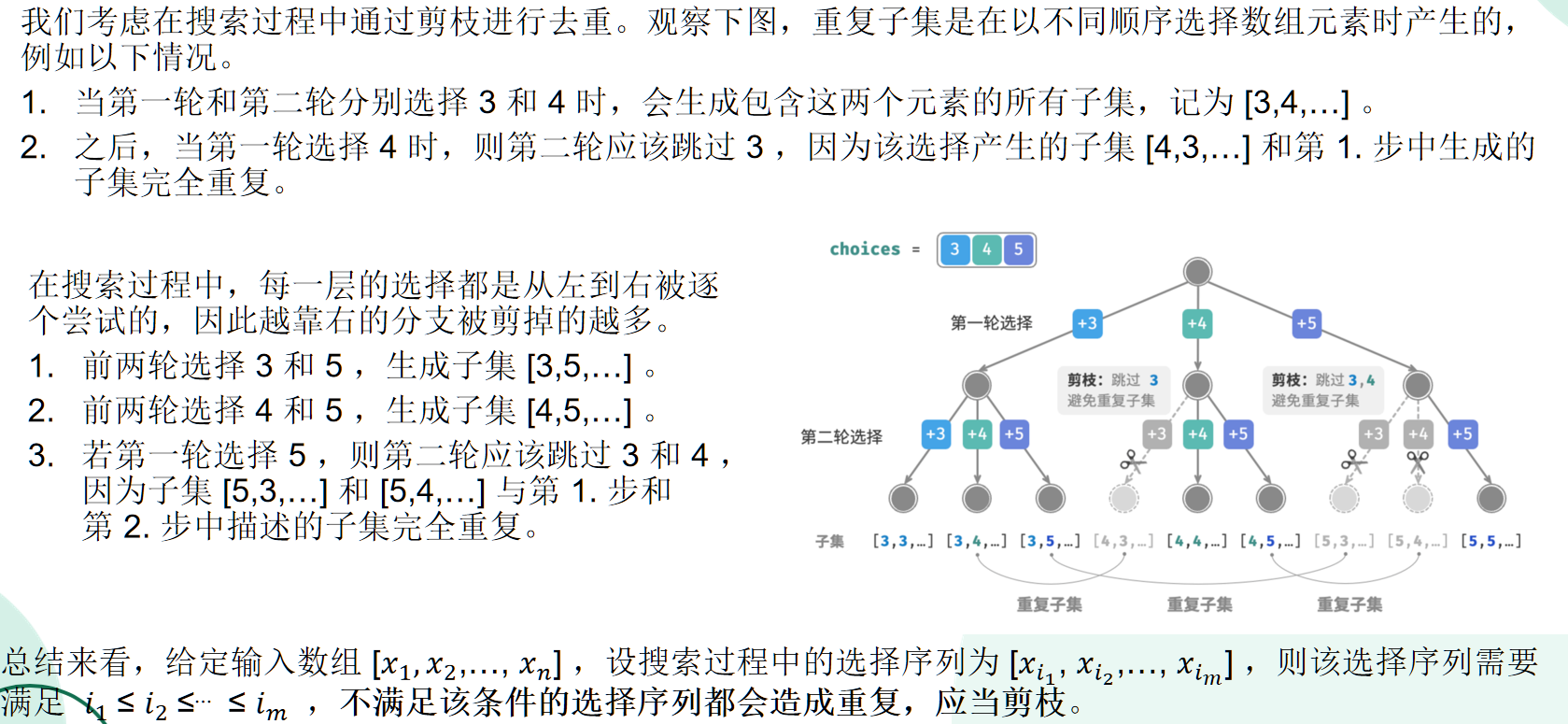
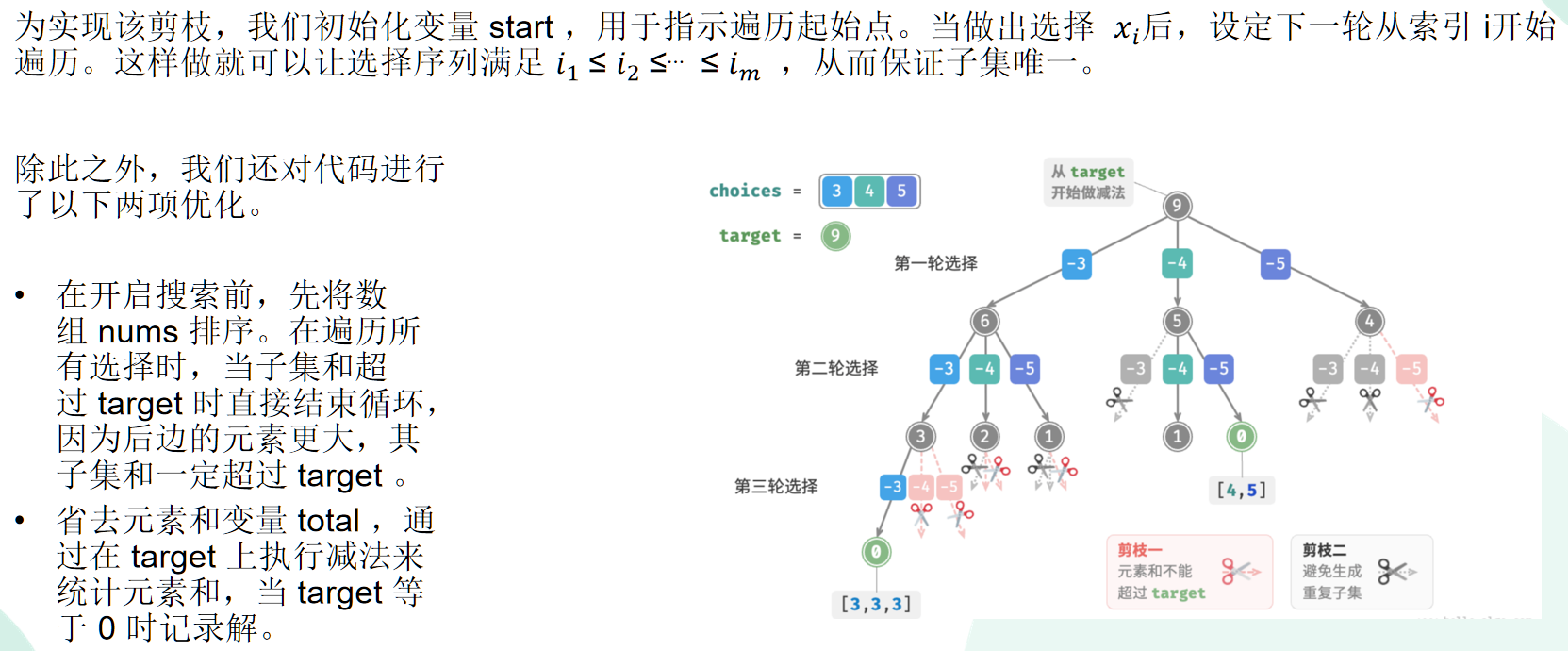
为了实现这种剪枝,使用一个 start 值记录每轮选择的起始下标,这样就能避免下标顺序错误的问题。代码如下:

有重复元素,但只能选择一次
问题:给定一个正整数数组 nums 和一个目标正整数 target ,请找出所有可能的组合,使得组合中的元素和等于 target 。给定数组可能包含重复元素,每个元素只可被选择一次。请以列表形式返回这些组合,列表中不应包含重复组合。
解决方法比较巧妙:
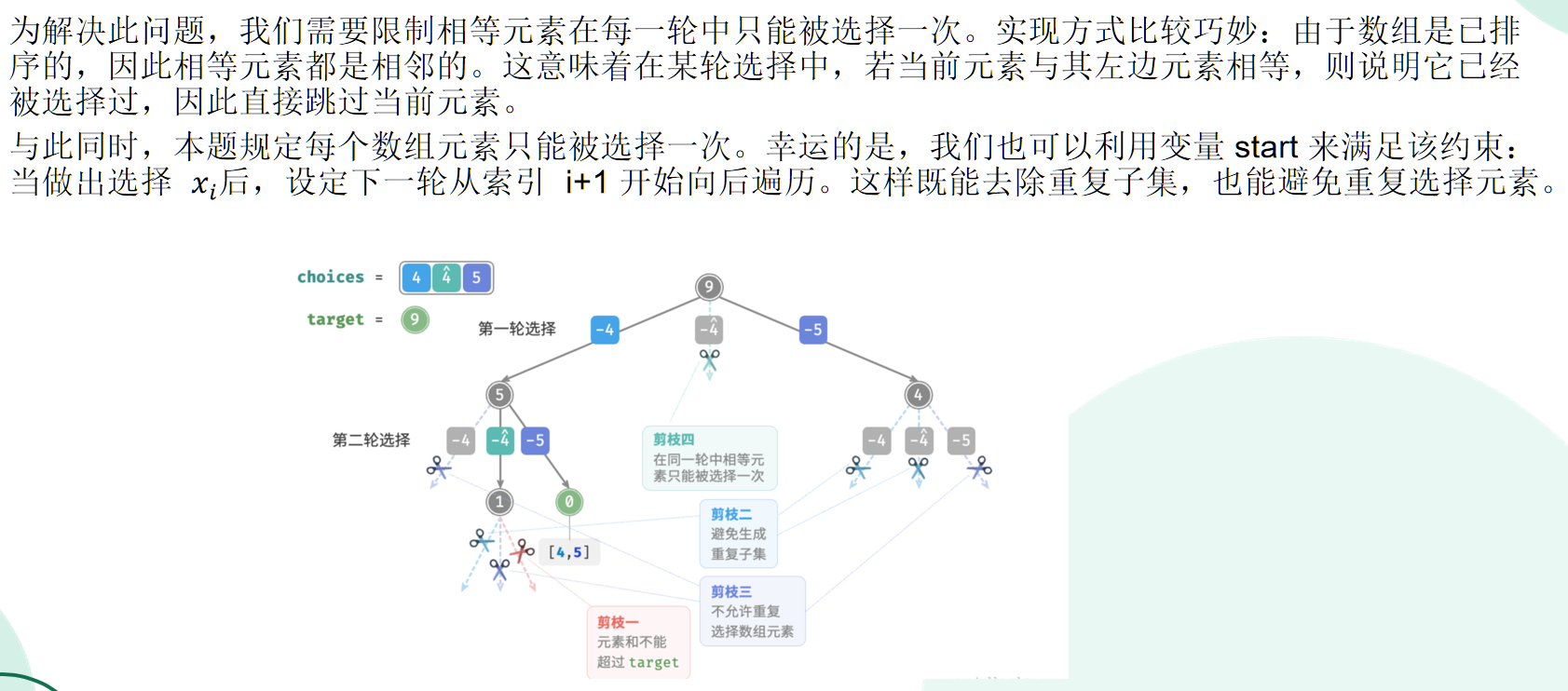
注:ppt中做法的”设定下一轮从索引i+1开始“可能有点问题,因为可能重复的元素不止出现两次,可能出现3次以上,这时不能简单地+1。我的想法:预处理一个哈希表next,记录每个值对应的下一个访问的起始下标:

(未实践,回头再说)
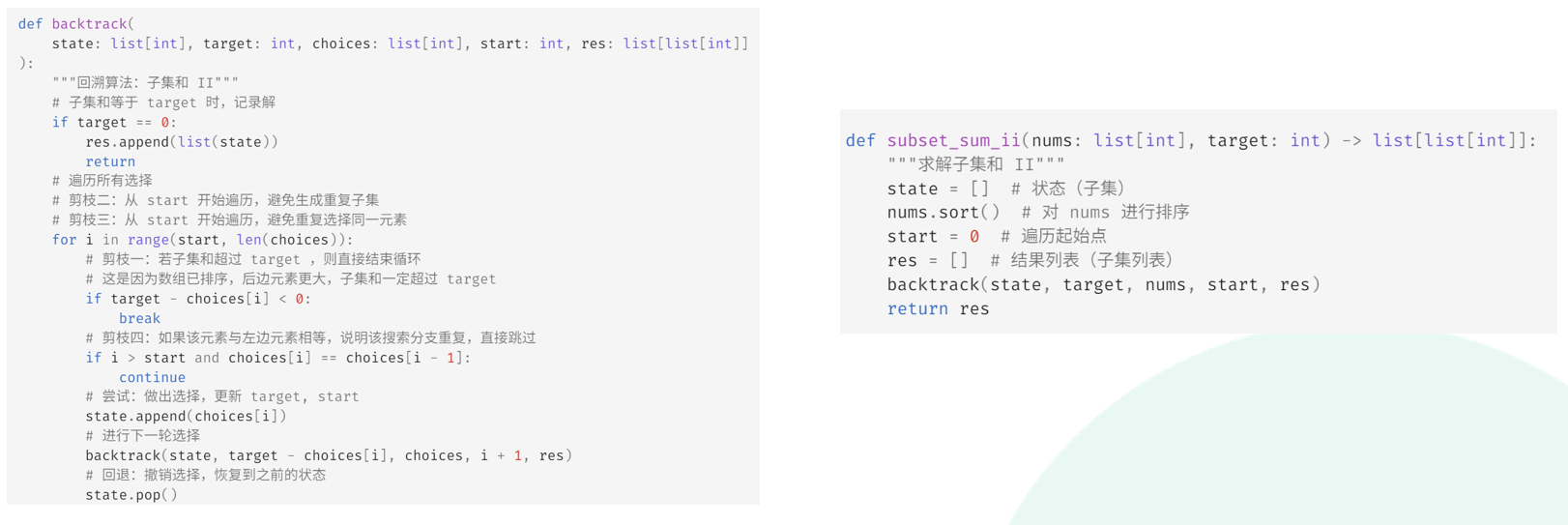
ppt的代码貌似使用一个continue的跳转进行去重(剪枝四):
N皇后问题
略,有若干方法,直接深搜即可
贴一些自己的方法,C语言写的:
位运算法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| #include <iostream>
#include <cmath>
#define MAX_N 51
using namespace std;
typedef unsigned long long ull;
int n, sum, flag, ans[MAX_N];
ull col, dia1, dia2;
void dfs(int step, ull col, ull dia1, ull dia2) {
if (step == n + 1) {
if (flag < 3) {
for (int i = 1; i <= n; ++i)
printf("%d ", ans[i]);
printf("\n");
flag++;
}
sum++;
return;
}
unsigned long long bits = (~(col | dia1 | dia2)) & ((1 << n) - 1);
unsigned long long bit;
while (bits) {
bit = bits & -bits;
ans[step] = log2(bit) + 1;
dfs(step + 1, col | bit, (dia1 | bit) << 1, (dia2 | bit) >> 1);
ans[step] = 0;
bits = bits & (bits - 1);
}
}
int main() {
cin >> n;
dfs(1, 0, 0, 0);
cout << sum;
return 0;
}
|
对角线数列映射法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| #include <iostream>
#define MAX_N 51
using namespace std;
int n, sum, flag, col[MAX_N + 1], dia1[MAX_N * 2], dia2[MAX_N * 2], ans[MAX_N + 1];
void dfs(int step) {
if (step == n + 1) {
if (flag < 3) {
for (int i = 1; i <= n; ++i)
printf("%d ", ans[i]);
printf("\n");
flag++;
}
sum++;
return;
}
for (int i = 1; i <= n; ++i) {
if (col[i] + dia1[i - step + n] + dia2[i + step - 1] == 0) {
col[i] = dia1[i - step + n] = dia2[i + step - 1] = 1;
ans[step] = i;
dfs(step + 1);
col[i] = dia1[i - step + n] = dia2[i + step - 1] = 0;
}
}
}
int main() {
cin >> n;
dfs(1);
cout << sum;
return 0;
}
|
对角线方程法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| #include <iostream>
#define MAX_N 51
using namespace std;
int n, sum, flag, ans[MAX_N];
void dfs(int step) {
if (step == n + 1) {
for (int i = 1; i <= n; ++i)
printf("%d ", ans[i]);
printf("\n");
flag++;
sum++;
return;
}
for (int i = 1; i <= n; ++i) {
bool flag2 = true;
if (step == 1) {
ans[step] = i;
dfs(step + 1);
} else {
for (int j = 1; j < step; ++j) {
if (((i + step == ans[j] + j) || (i - step == ans[j] - j) || (i == ans[j]))) {
flag2 = false;
break;
}
}
if (flag2) {
ans[step] = i;
dfs(step + 1);
}
}
}
}
int main() {
cin >> n;
dfs(1);
cout << sum;
return 0;
}
|
注:本文参考自课程ppt
 wechat
wechat alipay
alipay