复杂网络
PageRank算法
注:参考自手把手图文并茂教你掌握 PageRank 算法-CSDN博客、PageRank - 维基百科,自由的百科全书PageRank - 维基百科,自由的百科全书、谷歌PageRank算法的工作原理:理解搜索引擎排名的关键 - Spanning Tree_哔哩哔哩_bilibili
概述
PageRank算法是Google创始人Larry Page和Sergey Brin在斯坦福大学时提出的,又叫PR。是对搜索引擎搜索结果中的网页进行排名的一种算法。PR 值是表示一个网页重要性的因子。
PageRank本质上是一种以网页之间的超链接个数和质量作为主要因素粗略地分析网页的重要性的算法。其基本假设是:
- 数量假设:更重要的页面往往更多地被其他页面引用。也就是说,一个网页接受到的其他网页指向的入链(in-links)越多,说明该网页越重要。
- 质量假设:当一个质量高的网页指向(out-links)一个网页,说明这个被指的网页重要。其将从A页面到B页面的链接解释为“A页面给B页面投票”,并根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票对象的等级来决定被投票页面的等级。简单的说,一个高等级的页面可以提升其他低等级的页面。
基本过程
每个网页都有一定的票数,初始为,每次循环中都尝试对其出链指向的网页进行投票,投票的方法是将自己的票数按照出链数量平分,然后将其加到其所指向的页面。
转换一下关注对象,每轮循环计算每个网页的新票数,就是计算一个新的PR贡献值加到自己当前的PR上,公式如下:
其中:
- :网页a的某个入链对应的网页的PR值(这个网页所能为其他网页贡献的总PR值)
- :这个网页的总出链数(因为要平分其PR值)
例如:
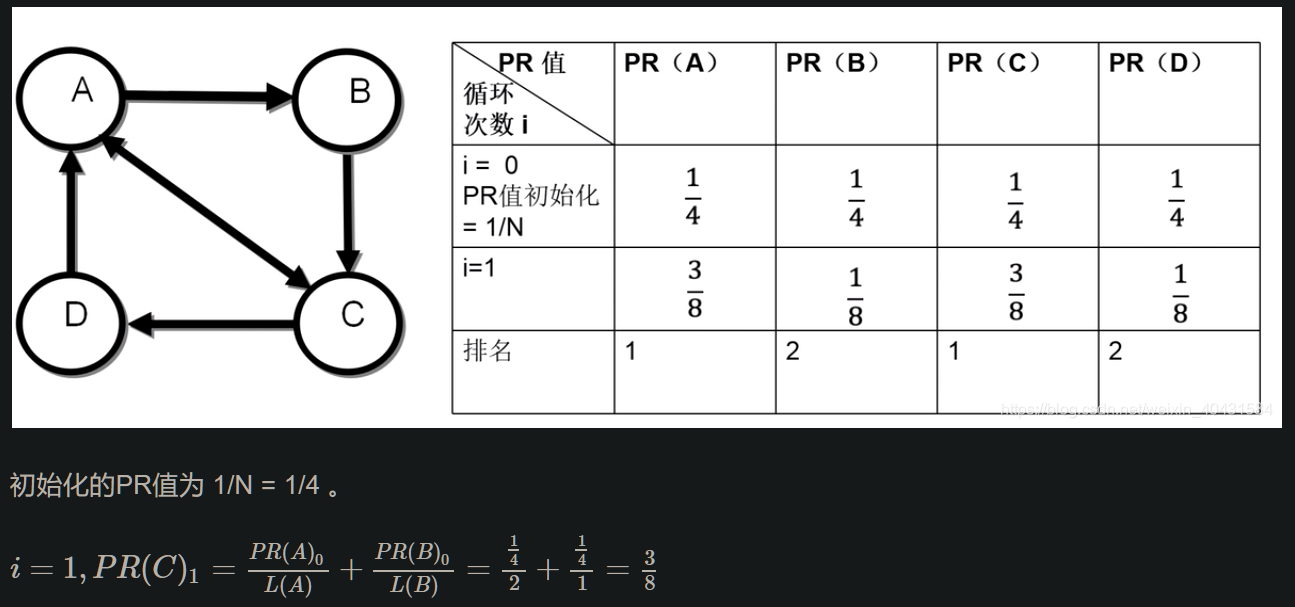
此外,这个计算过程也可以使用矩阵来描述:

另一方面,由于有的网页并没有出链,它们会将其他网页的PR值逐渐“吞噬掉”:
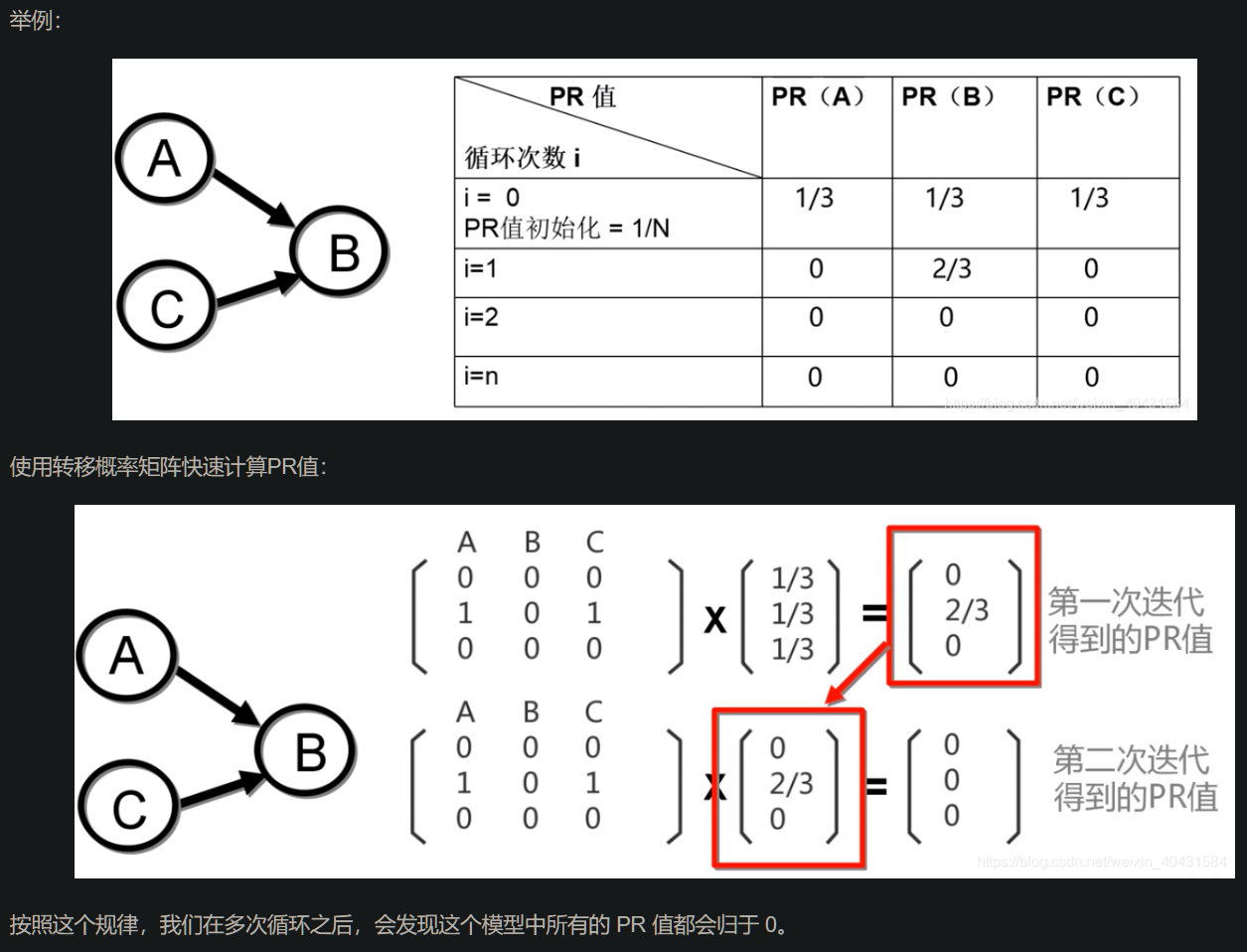
解决办法是认为此类节点链接到集合中所有的网页(无论是否相关),使得这类网页的PR值将被所有网页均分。
此外,使用一个阻尼系数,表示任意时刻,用户访问到某页面后继续访问下一个页面的概率,相对应地,则是用户停止点击,随机浏览新网页的概率。 的大小由一般上网者使用浏览器书签功能的频率的平均值估算得到。这个随机值能够避免算法只能在搜索结果的一个子图(该子图中所有网页均没有出链能到达其他的网页)中徘徊。
大致的过程如上,至于具体的公式未总结(回头再说吧,说是考概念题,具体公式可能不考?)
谱聚类
基本概念
无向带权图:

拉普拉斯矩阵:

其中A为邻接矩阵。
无向图切图:
对于无向图G的切图,我们的目标是将图G(V,E)切成相互没有连接的k个子图,每个子图点的集合为:
,它们满足,且
对于任意两个子图点的集合,我们定义A和B之间的切图权重为:
那么对于,k个子图的集合,定义切图为:
其中为的补集
RatioCut切图
RatioCut切图为了避免上述最小切图,对每个切图不光考虑最小化,它还同时考虑最大化每个子图点的个数,即:
具体做法:



其中 为矩阵的迹。(看不懂,下一个)
NCut切图
由于子图样本的个数多并不一定权重就大,我们切图时基于权重也更合我们的目标,因此一般来说Ncut切图优于RatioCut切图。
NCut切图和RatioCut切图很相似,就是把分母换掉:
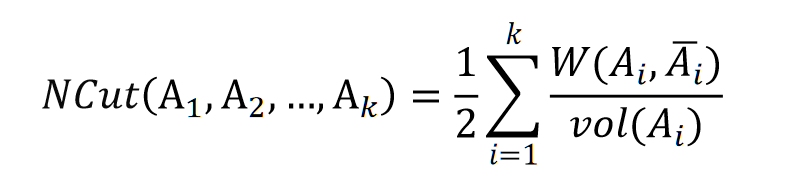
同时NCut的指示向量也做了修改:
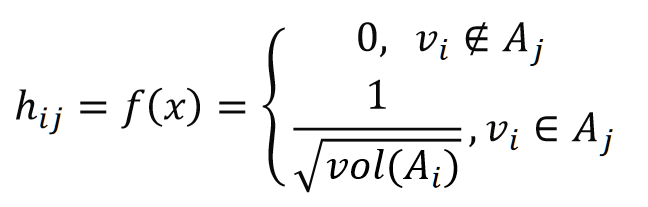
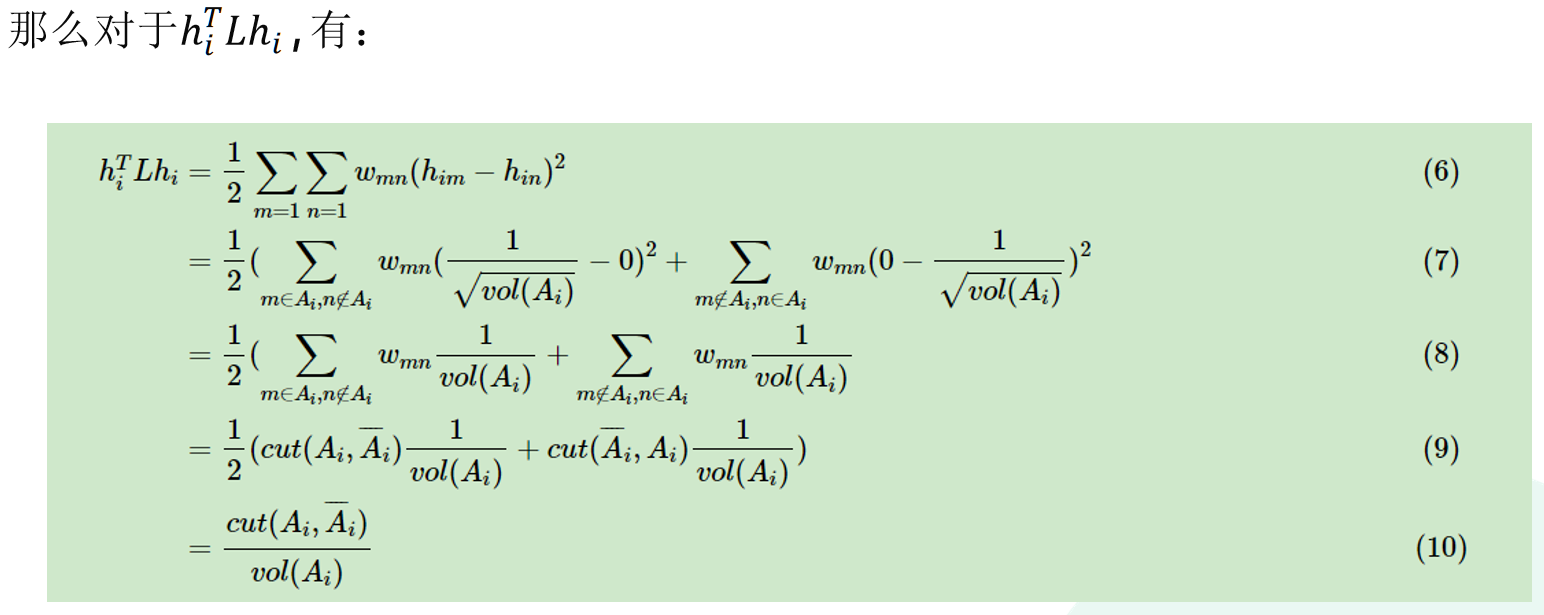

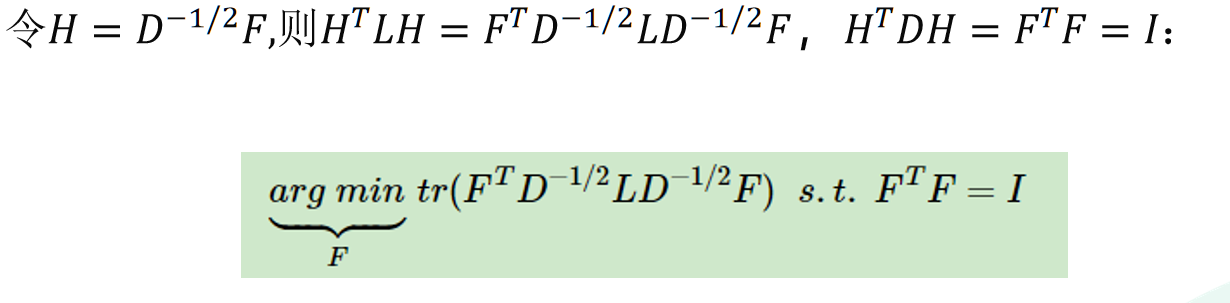
算法基本流程

注:本文参考自课程ppt
 wechat
wechat alipay
alipay