C语言教程-3_1-数据类型
为什么要有数据类型
如果你能想到这个问题,那么恭喜你意识到了低级语言和高级语言的区别。机器语言自然不必多说,到了汇编语言,仍然没有发展出数据类型这个概念—一切都是按照二进制串逐字节进行处理的。也就是说,汇编语言本身并不关心某个数据的类型,程序员需要自行根据需求,对不同类型的数据进行处理。
以下是8086汇编代码的一个片段:
1 | ; 8086汇编 |
很容易就能想到这样的开发方式的困难与繁琐。随后出现的高级语言,不仅在语法上接近自然语言,在对数据存储的角度,也考虑的十分周到。C语言中出现了(并不是第一个)基本数据类型,用以区别不同类型的数据,从而在底层进行不同的处理—例如浮点数和整数的底层存储原理完全不同,但是它们都共享同一个加法运算符 + 进行加法运算。
以下是一个C语言程序的例子:
1 |
|
实际场景中,不同的数据需要不同的操作,例如:日期必须为整数,汇率需要使用浮点数等等。
编程语言对各种数据的类型加以区分,有助于我们更精确地描述问题,提高编程的效率。此外,严格对数据类型加以区分也能够避免写出有歧义的程序,大大提高程序的健壮性。
此外,从语言层面来讲,高级语言的编译器(或解释器)都会提供对应的代码检查,数据类型为代码检查提供了更多的信息,确保不同数据只能进行其相应的某些运算,从而避免(潜在的)不合法的操作。
需要事先说明的是,C语言的类型系统并非那么严格,尽管它给了C开发者最大限度的自由度,但是相应地也导致了不安全的类型系统作为代价。C并没有出于各种安全考虑而作出各种限制,C认为,避免这些潜在的安全问题是程序员自己的责任,这与后来的以安全性著称的各种语言完全不同。
C语言支持的数据类型
C语言内置的数据类型有如下几种:
- 整型:存储整数,分为有符号数和无符号数两种,无符号数只能存储非负数;
- 浮点数:存储有限小数,精度有限,无法存储圆周率或者1/3这样的无限小数;
- 字符型:本质上是整型的一种,存储字符的整数编码;
- 数组:存储若干同类型的值(可以类比数学中的数列),值的数量和具体的类型取决于数组的类型;
- 结构体:是若干个特定的值的集合,构成一个整体;
- 枚举:定义一组具有离散值的常量,枚举类型的变量在某一时刻只能是这些值中的某一个;
- 联合:联合体也常称为共用体,允许在相同的内存位置存储不同的数据类型,但任何时候只能有一个成员具有有效值;
- 指针:C语言中最核心的类型,本质上是一个无符号整形,它是内存地址的高级抽象,一个指针变量可以存储一个特定类型的地址值,也就是指针(值);
不同的数据类型用来存储不同类型的值,并且彼此之间可以进行一定程度上的转换。
整型
整型,即存储整数值的类型。C语言根据实际需要,对整型做出了几种范围划分,每种整型类型都有不同的存储范围。
作为常识引入,我们有:
- 1 字节 = 8位(二进制位)
- 现在的电子计算机是二进制的
- 计算机存储任何数据都是离散的
- 整数是离散的
所以很容易理解:计算机中的整数是以二进制表示的,不同范围的整数所使用的二进制位数不同,所以整型类型的各种数据范围都是2的幂次方,即每种整型变量都是由若干个二进制位组成的。
C语言提供的整型类型分为两种,即有符号和无符号。有符号为:
1 | signed short 短整型 共2字节/16位 范围 -2^15~2^15-1 |
上面的所有的类型前面都有一个signed关键字,代表这个类型是有符号的(正负号),该关键字是默认添加的,也就是说可以省略,默认创建的整型变量都是有符号的。
同理,对应就有一系列无符号类型(只要把signed替换为unsigned),例如:
1 | unsigned short |
接下来讨论的数据范围的事情就要涉及到一点底层的知识了(其实没多少,需要自己去看补码的知识—见CSAPP(《深入理解计算机系统》)):
我们知道对于同样的一字节有:
只表示正数
1字节—8个bit位—最多能唯一表示0~255(正数)这些数
00000000 原码
0/1 两种状态的全部组合有 2^8=256种状态
同时表示正负数
首先来看一个问题:
我们有1字节,想要最大限度的存储整数—带一个符号signed位+剩下7位有效数字,那么对于0这个数有:
0 0000000 +0
1 0000000 -0
可以发现,如果我们仅仅简单的将各个数的二进制表示来存储的话,那么就会遇到这个问题,即00000000和10000000这两个编码都表示0,且一个是+0,一个是-0,显然从数学上是完全相等的,但是问题就在于,在计算机中,一个整数的编码必须是唯一的,那么我们必须要解决这个正负零的问题。解决的方法就是将10000000解释为其他数,我们引入补码这种表示方法,将10000000解释为-128:
0 0000000 +0
1 0000000 -128 计算机补码
我们将256中状态分成几部分:
256=128(负数)+127(正数)+1(原点0)
也就是说我们实际上能够存储的整数范围就是-128~127
其实就是 128=2^7—8位数实际上只有7位用来存储真正的数
同理16位—1位符号位+15位有效数字
0 0000000 00000000
那么可以推出对于k位有符号数,其存储范围是
注:这里只讨论了数据范围,暂时没有讨论补码的问题,感兴趣可以去看CSAPP中的相关章节,或者觉得看不懂百度也行,具体(预计)会在位运算进行讨论
浮点数
无法精确存储!!!无法精确存储!!!无法精确存储!!!重要的事情说3遍
浮点数的存储比整数要复杂的多,这并不是C语言的特性,而是计算机对浮点数的存储方式与整数完全不同。根本的原因在于计算机中一切值都是离散的,无法直接存储像循环小数这样的值,只能以某种形式近似表示。
现在的浮点数存储已经标准化,都遵循IEEE754标准(具体内容可以自行查询)。
IEEE754标准浮点数有两种,一种是32位的浮点数IEEE754,另一种则是64位的浮点数IEEE754-64。
IEEE754浮点数基于科学计数法表示,这让浮点数的存储范围很大(64位浮点数存储范围高达10的308次方),但是有效数字很少(32位保证十进制的6位有效数字,64位保证十进制的15位有效数字,注意这是近似到十进制的,因为浮点数是以二进制存储的)
注:IEEE754无法精确表示无限小数,但可以表示无穷大和NaN(not a number)
C语言的浮点数主要有两种:
1 | double 双精度浮点型 8字节/64位 精度16 最多小数点后6位 |
还有一种用的很少的long double,在现在的机器中精度更高,但是过去是用于解决兼容性问题引入的,使用较少。
讨论到浮点数,这里举一个例子:
1 |
|
可以看出实际上浮点数是无法精确存储的,但是越接近0,分布越密集,也就越精确
字符型
字符只有2种:
1 | (signed) char 注意:极个别编译器默认为unsigned char 字符类型 1字节 实际上就类似是一个1字节的int,实际使用中一般需要指定符号 |
字符实际上存的是字符的ASCII码值(正整数)— -128~127
-128------------0-------------127(环—溢出问题)
事实上,字符类型就是一个单字节的整数值,当在需要使用无符号单字节整数时,往往使用 typedef unsigned char byte; 进行代替。
ASCII码
机器只认识二进制数据,并不认识一个个给我们看的字符,这意味着我们需要把各种字符对应地转换为一个数字.
ASCII码就是最常用的,针对拉丁字符(英文字符)的编码,一共有128个,即2^7个二进制位就能完全表示.
char变量存储一个字符,也就是存储其对应的ASCII码,由于一个char变量占用1个字节,有8个二进制位,所以足以存储一个码值,同时需要注意的是,由于2^8=256,所以最高位不会被使用,这意味着我们可能将其正常用于符号位.
事实上,一般情况下,char类型实际上等价于signed char类型.
ASCII码表请百度查找.
如何存储一个字符
char实际上存储的是字符的ASCII码,这也是他可以参与整数运算的原因.
但是,我们仍然可以直观地将一个字符赋值给char变量.
C语言中,单个的字符需要用一对''来包括起来,他们是一个整体,例如字符A在C语言中表示为'A'.
也就是说,我们简单地将字符加上一对''即可将其赋值给一个char变量:
1 |
|
其中,printf中使用%c来输出一个字符,如果我们仍然使用%d,即输出整数的方式来输出一个字符,那么会输出其ASCII码:
1 |
|
那么反过来,我们当然可以将一个0~127的整数作为ASCII码赋值给char变量,甚至将一个整数在printf中以%c来解释:
1 |
|
使用转义字符来处理特殊字符
但不是所有的字符都能直接放在单引号内,例如单引号本身:
1 |
|
对于这些字符,我们需要使用转义字符来表示,即将其转义为一般的字符,而不是作为C语言语法的一部分.
要想使用一个转义字符,只需要简单地在想表示的字符前加一个反斜杠\即可,例如上面的单引号就可以这样表示:
'\'',这是一个整体,仅仅表示一个单引号
同时,由于反斜杠用于转义,所以它本身也是一个特殊字符,同样,我们在其前面加上一个\来转义它:
'\\',同样,这是一个整体,仅仅表示一个反斜杠
有关转义字符还有很多,例如字符串使用一对""来包括,这时候字符串内部出现的"自然也需要转义.
另一方面,有一些不可见字符,即空白字符,也需要转义,例如'\n'代表一个换行,'\t'代表一个制表符(通常等价于4个空格).
我们甚至可以将数字放到字符中,尽管单个的字符我们可以直接用一个数值来表示,但是如果是字符串,这将非常重要!
转义字符如下:

字符常量
同时还有一个很多书不会提到,或者说讲的不明确的问题,那就是字符常量到底和int一不一样,这里举一个代码例子,要用到sizeof运算符:
1 |
|
这里使用sizeof关键字计算操作数的大小(宽度),也就是占用几字节.
可以发现,单个字符常量/单个字符变量都占用1字节,而int常量(变量)占用4字节
但是,一旦char加入了和int整型的运算,那么结果的大小就会立即变成4字节
甚至只是两个字符常量进行相加(字符对应的ASCII码值相加,而不是连接),结果也立即提升为4字节
所以我们可以证实:在C语言中,单个的字符常量是1个字节,但是一旦参与运算,就立即提升为4字节,也就是说被解释为(当做)4字节的int常量参与运算
换句话说,你完全可以把C语言中的字符常量当成int来看待!!!这是一个很重要的特性,很多教材,书中都没有提到,或者讲解的不够清晰.
其他特殊类型
其他的特殊类型非常重要,但是这里先不进行讲解,本文的主要目的是要让各位建立起对数据类型及其表示范围的概念,后面的几种类型会单独分章节进行讨论,特别是指针,堪称C语言的灵魂,放在好几章里讲解都不为过,甚至在后面的各种应用都离不开指针.
C语言的数据
C语言中,数据有两种,即常量和变量;
还有一种实际上属于变量,但是常常被称为常量,或者常变量的数据,就是在变量声明的适当位置加上const这个关键字;
另外有一种特殊的常量,叫做宏定义,实际上是一种预处理,只是单纯的文本替换,同样十分重要.
如何声明一个变量
注:有关声明的详细内容可见https://zh.cppreference.com/w/c/language/declarations,其他声明将会在后续知识的讲解中逐渐插入.
变量,顾名思义,就是可以变化的量,用于在程序中存储不断变化的值,或者用于接受我们输入的值(在运行前不确定).
并且变量不同于常量,在使用前必须进行声明—提前告知编译器这里需要使用到一个变量(需要进行内存分配).
如前所述,C语言是静态类型语言,声明一个变量,则必须声明其类型(编译前就必须确定其类型):
1 |
|
变量的声明方法
一个变量声明,遵循以下格式:
<类型> <合法的标识符名>;
类型即为上面所述的各种合法的内置类型,或者是自定义的类型(例如结构体类型,枚举类型等等);
标识符的命名规则
这里再重新说明一下:
标识符即为变量名,在C语言中,标识符的命名有如下几条规则,不遵循这几条规则的标识符均不合法(或者不合适):
1 | 1 标识符必须以字母a-z、 A-Z或下划线开头,后面可跟任意个(可为0)字符,这些字符可以是字母、下划线和数字,其他字符不允许出现在标识符中 |
不好意思地指出,本人的英语水平不太好,而且各种标识符(包括但不限于变量名,函数名,结构体类型,宏定义等)都习惯下划线命名法,可能较长.但希望宁肯变量名长点,也不要一大堆a,b,c,d,e,f,g之类的扔上去,否则以后回头看代码遭罪的只会是你自己.
变量从哪里声明
这里的知识可能涉及到一点作用域和生命周期的问题,但是这里先不讲解—依旧,知识都是交叉的,在该讲什么的时候就讲什么.
其实核心的就是一句话:在你使用到该变量之前提前声明好他
例如上面的double pi=3.14;我们需要在后面进行输出其值,所以必须在使用printf之前进行该变量的声明,同时对其进行初始化(初始化为3.14).这里的pi在main函数中声明,所以pi也叫局部变量,换句话说,在其他地方(其他函数中)是不允许使用该变量的(找不到pi),因为pi是main()函数私有的:
1 |
|
上面这个程序无法通过编译,因为在test函数中无法访问到pi这个变量.
但是如果我们把pi放在main()函数的前面,同时在任何函数的外面,那么pi就成为了全局变量,任何函数(本源文件内)都有权限访问修改其值,并且pi在程序运行的整个过程一直存在而不会销毁(后面在作用域与生命周期的相关教程会详细解释):
1 |
|

这里的示例主要体现了两种pi的作用域的不同,暂未展示生命周期的问题,大家现在只需要知道:如果需要一个变量给所有的函数共享,那么请将他作为全局变量,但是,这种操作一定要慎重,除非迫不得已,最好不要将任何变量声明为全局变量—你有可能会在某个函数中不小心修改(破坏)其值—请绝对不要高估你的实力与判断.
如何使用一个常量
常量和变量的区别
其实这个问题很显而易见,常量就是不能(或者说不应该)被修改值的量,从逻辑的角度去想,如果某个要被使用到的值确定不会(甚至是绝对不能)被修改(例如宇宙的普朗克常量),那么何不将其直接作为常量写入呢,这是一种思路,下面按照这个思路来写一个求圆表面积的程序:
1 |
|
这里3.14就是一个浮点型的常量,我们直接将其硬编码到程序中.
但是有一个问题,如果我们手动指定pi的精度,那么pi就不得不每次进行修改,例如3.14,3.14159,3.1415926535,…如此直接修改程序就显得非常麻烦,而且每一个地方都要进行手动修改,十分繁琐,与其这样,我们还不如将其定义为一个变量.
但是不得不承认,这里的例子破坏了常量就是不能(或者说不应该)被修改值的量这个前提,但是我们为了说明问题,暂时违反一次…另一方面,我们并不是只有这两种选择,在C中,我们有一种特殊的定义"常量"的方法,那就是宏定义.
宏定义实际上只是完完全全的文本替换,他类似于你在文本编辑器中"ctrl+h"进行批量的文本替换,我们见如下示例:
1 |
|
宏定义的定义格式是这样:
#define <宏名> [要替换的内容,可为空]
那么在上面的代码中,我们将程序中所有的PI全部替换成3.14
可以发现,宏定义实际上是预处理指令(#号代表预处理),也就是说在编译前宏就已经被替换了,所以说宏只是单纯的文本替换
另一方面,宏处理是从上向下依次执行的,如果先执行的宏替换之后,替换的地方又出现了后执行的宏需要替换的地方,那么这个地方仍然会被再次进行处理,以此类推,直到所有的宏全部被替换完成.
关于宏的知识还有其他内容,有的用的比较少,有的现在还不能讲解,读者不妨自行查阅—例如"宏函数",“拼接宏”,"递归宏"等等高级(抽象)用法,有些其实基本不会用到,而有些会常常用到,需要不断的代码积累.
常量有哪些

实际上很简单的说,单个的数字(例如123,3等),单个的字符(例如'a'),单个的字符串(例如"hello world"),一些编译器预先定义好的常量(例如NULL,其值是0)这些都是合法的常量(或字面量)
常量的存储问题
接下来是常量的存储问题.和变量不同,常量存储在常量存储区,而不是像局部变量存储在栈区,全局,静态变量存储在全局(静态)存储区里等等.
而且字符串是在一个字符常量区中,而且对字符串常量的引用(注意不是C++的引用,而是指使用),实际上是一个指向字符串第一个字符的字符指针,而且一个C程序共享同一个字符串常量—这意味着如果两个字符指针指向同一个字符串常量,那么在内存中实际只有一个这个字符串常量的副本!!!更重要的是,对一个字符串常量进行修改的行为是未定义的!!!有关字符指针的内容会在指针或字符串的相关章节进行详细的讲解(一般的教材是不会讲的doge)
介于常量和变量之间—常变量的使用
常变量实质上就是变量,我们使用一个const关键字对变量进行修饰,让他的值不能够被修改:
1 |
|
const提供语言层面的保护,编译器会进行一定程度上的识别,如果有修改的行为会进行报错—除了使用指针进行强行修改,但是此时一般程序会直接终止.
关于const关键字相关的知识将在指针进行更加详细的讲解.
—WAHAHA,2023.9.21
如何使用数据
在此处,我们先引入最基本的几个运算:加减乘除和赋值
对于数据,必然要进行操作使用,我们可以使用最基本两种操作方式:
1.变量或常量之间可以进行组合运算,例如加减乘除等,并计算出一个最终的值
3.把计算出的最终的值赋值给一个左值(后面会介绍到左值,这里简单将左值理解为就是变量)
变量的初始化
数据的操作处理,主要和变量有关,常量作为辅助.那么一个变量,在进行操作之前,应当给他一个初始的值,我们把这种操作叫做初始化.
例如,我们想要定义一个pi的浮点型变量,并初始化为3.14,应该这样写:
1 | float pi = 3.14; |
也就是说,我们在声明这个变量的同时,直接在pi这个标识符后面跟一个=运算符,后面再跟其初始值即可.
这里的=叫做赋值运算符, 它的功能是将其右边的"值"赋值给左边的"变量".
另一方面,必须要注意的是,赋值运算符在这里实际上并不是赋值的操作,虽然我们使用了=运算符—这显然很符合我们的思维,但是正如标题所写,这里的操作叫做初始化而非赋值!
为变量赋值
我们在程序的运行当中,一些变量的值会发生变化,也就是说需要重新给他赋一个新的值,那么这时候的操作就叫做赋值,这里使用的=运算符才是真正的赋值含义.
这里仅仅先知道我们使用=运算符(C语言中这种用于运算操作的符号统称为运算符)对一个变量进行赋值即可.
例如,我们定义的一个变量原来是3,此时我们想要将其重新变为4,应该这样写:
1 | int var = 3; // 这里是初始化而非赋值 |
变量/常量间进行运算
注:由于仅仅学了几种基本类型,我们仅拿四则运算的运算符来举例,实际上C语言支持的运算符远远不仅于此.
很显然,我们使用+-*/这4个运算符进行四则运算,他们的运算行为和数学意义完全相同,例如如果除数是0则会出现错误.
例如:
1 |
|
显然,输出的结果是7
又如:
1 |
|
显然,输出的结果是4
再例如我们想要计算浮点数:
1 |
|
或者使用float(精度要求较低时):
1 |
|
注:实际上printf()函数会将所有的float类型值提升为double类型,因此用%lf输出float类型值也没有问题.
另外,我们可以连续进行使用:
1 |
|
从这里我们也能看出四则运算和其数学意义相同,乘除法的优先级依旧高于加减法,所以结果是13.
那么如果想要强制先运算a+b,我们加上小括号即可,同时小括号可嵌套使用!
1 |
|
这里涉及到运算符的优先级,同样,现在进行详细讲解还为时过早.
两种类型转换
前面我们分别举了整型计算和浮点型计算的例子,那么问题来了,这个程序输出的是什么:
1 |
|
如果你觉得输出的是1.5,那么很遗憾,你完全忽略了上面讲的数据类型的知识!
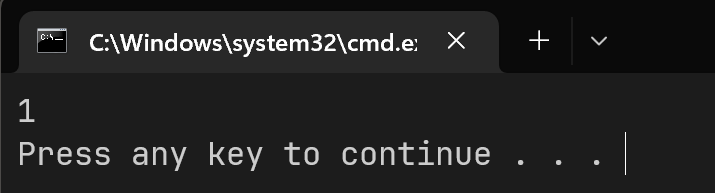
运行结果可能出乎你的预料,是1!原因很简单,a和b都是int类型,那么很自然的,C语言没有理由自动的为你将a/b作为一个double类型的值,而是只会是一个int,那么实际上1.5的0.5被忽略了,而且是直接舍弃,没有四舍五入.
换句话说, /运算符对于int变量,执行的叫做整除,这里的a/b相当于[a/b],这里的[]代表向下取整.
那么解决的办法也很简单,使用类型转换.
隐式类型转换
将a或b中的其中任何一个声明为double即可(或者两个都是double),此时,C语言会有一个类型提升,也就是说,其中那个精度较低的变量(int类型的那一个)会被提升为和另一个变量相同的精度更高的类型(double),此时,double类型的值就可以保留浮点:
1 |
|
输出结果为:

这里的"类型提升"实际上是一个隐式类型转换,顾名思义,C程序默默地将b提升为double.
转换对应的两种类型必须能够互相转换,否则会报错,例如:
1 |
|
不过,如果一种类型的值赋值给另一种类型的变量,如果可以转换过去的话,那么将不会报错,而是可能产生一个警告,但可以通过编译.
另外,必须注意的是,从高精度值向低精度值转换会损失信息:
1 |
|
显式(强制)类型转换
与之对应的,我们可以进行显式类型转换(或者说强制类型转换),使用方式是在要提升的值前加一对小括号,括号内写要转换为的类型:
1 |
|
此程序同样输出1.500000
需要注意的是,由于强制类型转换的优先级大于/运算符,因此实际上被强制类型转换的是a,然后b被隐式转换为double类型,和提升后的a进行运算,最终的结果是double类型.
类型转换与运算符
实际上,如果某个运算符的两个操作数类型不同,那么该运算符会先将精度更低的操作数隐式类型转换(也就是所谓的类型提升)为精度更高的操作数的类型,然后再以该类型进行运算,以保证类型匹配,同时避免精度损失.
当然,这种转换是有限度的,如果两种类型完全无法兼容,那么会报错.
附注
标准中对算数类型的定义
可以参阅
https://zh.cppreference.com/w/c/language/arithmetic_types
中的内容,对各种类型都有明确清晰的描述.
里面不仅有类型的用途,大小,并且还有它们取值范围的参考.
---WAHAHA
上一篇:[c语言教程-2-环境搭建](../2023bb3b8099b657/) 下一篇:[C语言教程-3_2-基本输入输出](../2023427f4611cc41/)
 wechat
wechat alipay
alipay