C语言教程-11-字符串
提要:
本章要讲解字符串的内容.同时会使用到前面基本输入输出一章中讲解的各种输入输出函数和数组,若不了解请自行复习.
注意:
本章需要的前置知识为:
1.彻底掌握C语言单个字符(字符变量)的相关知识,如果没有掌握,请回看前面的数据类型一章!
2.掌握一维数组的相关知识,如果没有掌握,请回看前面的数组一章!
什么是字符串
一个程序需要的不仅仅是针对问题进行计算,还需要和用户(程序的执行者)进行交互,例如在界面(控制台等)打印一个标题来显示程序名/打印一行提示等,这些信息往往都是一个个的字符,比如这一句话"This is a calculator",就是一个由字母,空格这样一个个的字符组成的序列,我们称之为字符串.
字符串的用途很多,最显而易见的就是作为和用户交互的信息进行输出.
此外,字符串也可以作为程序运算的对象,例如一个用于实现凯撒密码的程序,就要对密文字符串进行加密:
1 |
|
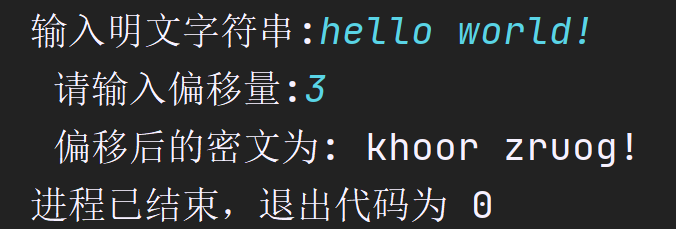
上面这个程序就使用gets()函数输入了一个字符串(可以包含空格),然后将字符串中的字母按照输入的偏移量(可以自行百度凯撒密码)进行变换加密.
任何高级编程语言都有针对字符串的功能支持,我们将对C语言的实现进行详细讲解.
C风格的字符串
首先必须提出的一点是,抛开平时简单的代码不谈,实际情况下,几乎所有的关于字符串的处理都不是什么易事.
这里说的处理不单单是对字符串进行替换,连接,删除等操作,更复杂的是面对用户时如何的正确处理输入输出.
初学者可能会在scanf,printf这两个函数上耗费大量的时间,不要紧,这两个函数没有那么难.
这一段内容的前置知识要求彻底掌握C语言单个字符的相关知识,如果没有掌握,请回看前面的数据类型一章!
字符串常量
如果我们仅仅是想要一个不变的字符串,可以使用字符串常量.
C语言中,字符串是由一对""和其包括起来的任意数量的字符组成.
例如,我们想要表示Hello world!这行字符串,就是这么写:
"Hello world!"
任何可以放到char变量中的字符,都可以出现在字符串中,需要注意的是:
转义字符依旧需要在字符串中转义,它和单个字符相同,只不过是和其他字符紧挨着放在一起了而已:
"hello\nwelcome!"这个字符串中的换行符'\n'尽管和其他字符连在一起,但是不影响C语言识别出它.
printf的第一个参数
前面讲过,使用printf()函数,我们可以直接输出一个字符串常量:
1 |
|
在之前,我们仅仅知道使用printf时,括号里第一个部分需要加上双引号,现在我们知道了,它是一个字符串.
前面所说的这是一个"格式化字符串",代表的是这个字符串的功能,其中形如%d,%s,%lf这样的字符组合并不是转义字符,而仅仅是在printf内部用于识别处理后面参数.
字符串的长度和占用空间
假设我们有如下字符串:
"hello world!\n"
1.那么这个字符串的长度是多少?
显然,可见字符有13个: 10个字母+1个标点+2个空白字符(中间的空格和末尾的换行)
所以这个字符串的长度为13.
2.那么存储这个字符串需要多少空间呢?(以字节为单位)
实际上,一个字符占用一个字节,那么13个字符就占用13个字节,但是问题并没有那么简单,事实上,我们需要14个字节去存储它.
因为一个字符串必须要有一个结束标志,来代表这个字符串到达结尾.那么C语言中,这个标志就是所谓的零字符'\0',注意和'0'区分!'\0'实际上就是一个0(只不过是一个字节),所以有时候我们也可以使用0来简写.
可以这样理解:为了取消特殊性,'\0'仍然是一个字符,这是一个转义字符,为了和字符'0'区别.
它同样占用一个字节,所以整个字符串需要14个字节去存储!
后面我们会讨论字符串的访问溢出问题.
字符串常量的使用问题
1.能否拼接?
字符串"Hello user1\n"由如下若干个字符连接而成:
'H','e','l','l','o',' ','u','s','e','r','1','\n'
但是遗憾的是,我们并不能将其使用+运算符进行拼接—读者可能使用过其他的一些语言,例如python,JavaScript,它们是可以使用+运算符拼接字符串的,因为他们将字符串视为一个对象!然而C语言作为一门面向过程的语言,自然是对此没有支持.
2.可以用单引号?
更为错误的是,我们必须使用"",而不是''来包括一个字符串,字符和字符串是不一样的—字符属于基本类型,而C语言没有任何基本类型来直接存储字符串!
3.不是对象,那它是什么?
这里可能有点"超纲",但是有必要指出,C语言中的字符串常量的类型是一个字符指针(指向的空间内容为const),这个字符指针的值为字符串中第一个字符的存储地址!
例如"hello world",我们对其进行使用的时候,实际上我们仅仅是获取到了这个字符串常量的指针(地址)而已,也就是'h'的存储地址,常量字符串存储在常量区,我们不能对其进行修改.
同样很无奈,想要深入探索这个问题,必须等到后面讲解到指针才行.
4.字符串怎么修改?
第3点中指出,字符串常量是无法被修改的,因为其类型为const char*,更根本的原因是它存储在内存的常量区,修改它的结果是不确定的,甚至会导致程序直接崩溃.
那么如何使用可修改的字符串呢,下面来讲解.
可修改的字符串
尽管字符串很重要,但是很遗憾的是,C语言并没有任何专门存储字符串的数据类型,因为C太过底层.
我们分析一下字符串的结构就可以看出,实际上每一个字符都单独地占用一个字节(暂时仅仅考虑英文字符集),并且这些字符都是连续排列的,直到遇到一个'\0'结束,也就是末尾一个字节是全0.
那么我们很容易想到,我们可以利用C语言的数组来进行存储一个字符串,仅需要将数组的元素类型设置为char即可:
1 |
|
这里使用一个存储char类型元素的数组来存储这个字符串,C语言提供了一种方便的写法,可以使用一个字符串常量对其进行初始化,这样,我们就得到了这个字符串常量的一个副本,将其存储在str数组中.
我们当然也可以这样写:
1 | char str[15] = { |
显然这种方法不如第一种方便,最后面的'\0'可省略,但是不建议,显式加上字符串结束符是一个好习惯.
同样,尽管我们这样使用数组来存储一个字符串,但是他还是一个数组,这意味着我们可以使用一切数组的用法来对其进行操作,例如我们可以使用下标的方式获取到某一个字符,并且对其进行修改,十分简单,读者请自行尝试.
重点:数组的问题
数组的大小和溢出
一定要注意的是,字符串后面会有一个'\0'结束符,它必须纳入数组长度的考虑,例如,我们至少需要:
1 | char str[14] = "hello world!\n"; |
我们如果使用printf("%s", str);对其进行输出,结果是这样的:

没有问题,最后会有一个换行.但是,如果我们仅仅考虑了字符串的长度13,结果就会变得十分意外:
1 | char str[13] = "hello world!\n"; |
运行结果是这样的:
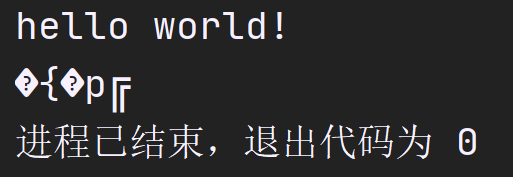
可以发现,在正常输出了原来的字符后,末尾又输出了一些奇怪的字符,这意味着在访问数组时,并没有访问到'\0'—由于数组长度太短,没能够存储进去,这就导致字符数组中仅仅保存了前面的字符,而没有正确的结束标志.
这样的后果就是,当字符串在输出时,会一直向后访问,直到在相邻的内存中遇到一个全0的字节!
进一步,如果我们多次运行这个程序呢?结果会是一样的吗?
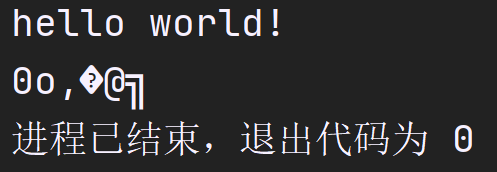
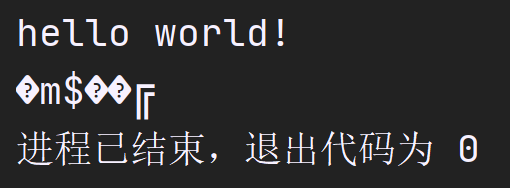
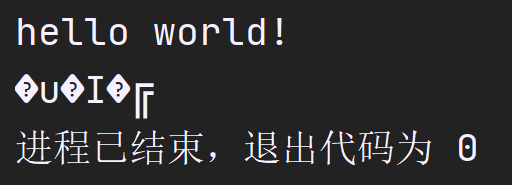
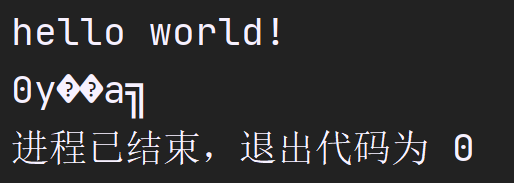
可以发现,后面输出的乱码完全是随机的,事实上,这个程序:
1 |
|
我们对其进行输出,已经发生了栈溢出,非要深究的话,我们前面输出的那些乱码全部都是程序运行时栈的内容,由于str是局部变量,所以它在main函数的栈中分配,我们访问到数组末尾,并没有发现结束符,printf就会错误地认为字符串并没有结束,进而继续向后访问(实际上是继续向下访问更高地址的数据,因为堆栈是从高地址向低地址增长)
每次程序运行,调用栈的相关数据都是不一样的,因为操作系统(这里是Windows)每次运行这个程序,都会为其分配不同位置的内存,这就导致每次错误访问到的数据不同.
总之,在使用字符数组来保存字符串的时候,千万要注意数组的长度,确保至少能刚好存下这个字符串.
然而,我们知道声明数组时,有时可以省略长度,只要我们对其进行了初始化,这意味着我们可以让编译器自动计算长度:
1 |
|
运行结果:
这样没有任何问题,如不理解请复习数组.
再探ASCII码-char和中文
char的符号
前面讲解过,char变量存储的实际上是一个字符的ASCII码,其值范围是0~127.
但是char是一个字节,意味着有8位,如果按照无符号去存,范围是0~255,显然多了一倍.相反地,如果按照有符号去存,其值范围为-128~127.同样的8个二进制位以不同的解释方式去处理,结果是不同的.
显然,上面这两种情况分别对应的unsigned char和signed char,这两种类型和char类型并不相同,它们互相独立.也许我解释的不够明确,标准如此说:

重点是第3点.它指出,标准并未规定char必须和这两种解释方式(有符号和无符号)中的某一种等价.标准将这个问题交给具体的实现(C编译器的编写者)来处理,不同的实现可能不同,但是大多数情况下,char往往是有符号的,也就是说它和signed char等价.
从现在开始,本教程默认char类型和signed char等价,亦即认为char有符号.
溢出问题
尽管char类型一般被解释为有符号的,但是不影响其8位仍然有256种状态,我们其实将负数全部舍弃不用,仅仅使用正数部分即可表示所有的ASCII码.
但是,这又牵扯出一个溢出问题—尽管我们原则上不使用负数,但是仍然有可能无意或有意地把一个char变量变成负数.
例如,字符’A’对应ASCII码65,我们对其加32,让其变成97,也就是’a’,这就实现了大小写转换.
但是,如果我们"意外地"(有意地)对其加了100,那么实际上结果并不是165,而是-91.
这里发生了一个上溢,由于计算机中整数加法实际上是补码加法,存在正溢出和负溢出,简单的说就是当数值超出了能够表示的上界和下界,就会从下界和上界进行回绕,溢出了多少就绕回多少.
165比char的上界127多出了38,则从下界-128回绕38,-128视为已经回绕了1,那么就要从-128再加上37,最后的结果就是-91.
下溢也是同理,总之,对于正常的英文字符而言,溢出到了负数意味着不是一个合法的字符,对其强行进行解释也只会显示一个乱码:
1 |
|
运行结果为:

非英文字符集支持
当然,并不是所有的字符全部都是英文的,这时候,ASCII码便不再适用,因为,此时想要正确表示一个字符,可能需要2个字节,甚至3到4个字节才能够保存.
例如在GBK编码中,一个中文字符需要两个字节才能存储,更为通用的UTF8编码中,则需要3个字节!
必须提前说明,Windows默认编码为GBK2312,而更加通用的字符集则是UFT8,这两种编码互不兼容,读者如果要在程序中加入中文字符(其他非英文字符同理),一定要注意编码的统一!
大部分初学者都是使用windows,所以各位的程序中的中文字符一般都是GB2312(或GBK),而许多软件(例如VSCode)内置的运行终端默认的编码都是UTF8,这就往往会导致新手最头疼的乱码问题.
解决的办法一般有两种思路:
- 将终端的编码设置为gbk,与源代码一起全部统一为GBK.
- 将源代码转换为UTF8,一起统一为UFT8.
读者可以自行百度不同软件的解决方案,笔者这里使用了一个不是很好的方法:开启windows的全局UTF8支持,这样就解决了乱码问题,但是新问题就是,许多朋友的代码都是gbk,直接运行就会导致乱码,而且chcp 936也无可奈何,暂时还未解决.
所以还是建议去将软件的终端改为GBK相对会好一点.
但是Linux默认UFT8…这就很难受…
另一方面,由于中文字符不能单靠一个字符去存储,C标准定义了wchar_t这些类型来支持宽字符,这里就不介绍了,因为用起来有点麻烦.
我们对于中文字符,可以直接存入字符串,尽管一个char不能保存一个中文字符,但是2个(甚至是3个)连在一起就可以实现:
1 |
|
运行结果为:

可以看出,除了中间的空格和末尾的感叹号外,其他的字符都不是合法的ASCII字符—它们都是各个中文字符的一部分.
再例如,我们如果这样写代码,是可以输出一个正确的中文字符的:
1 |
|

这3个字符组合起来就是一个完整的'你',当然,这样写仅仅是作为一个示例而已.
掌握了如何使用字符串,我们就可以编写出更加人性化的程序,为用户提供更多的提示信息;不仅如此,我们还为编写字符处理程序打下了基础.
---WAHAHA
上一篇:C语言教程-10-数组
下一篇:C语言教程-12_1-初识函数
 wechat
wechat alipay
alipay