指针和数组的关系
数组的本质
在C/C++中,数组就是相同类型变量的有序集合,数组在一段连续的内存空间中存储他们—也就是数组的元素.
这段内存空间既可以在栈区,也可以在堆区,甚至可以在静态存储区.
不管在哪里分配,总之我们只需要知道这个数组的首地址和数组的长度,还有这个数组的元素大小,就可以确定这个数组.总之,我们就是为了能够统一存储一系列同类型的值.
指针的本质
指针的本质就是地址,而这个地址就是一个值,我们为了方便,一般将其以16进制进行显示.
C/C++中的指针的用途就是用来标识一个数据对象.一个数据对象有着他自己的长度(占用多少字节),指向这个数据对象的指针的类型就可以用于标识其长度.当然,还可以限定关于他的运算.
指针和地址
常常有人在争论:“指针不是地址,因为指针有类型”.
这句话可以说没有什么问题,但是他限定了讨论范围仅仅在C/C++语言中的指针.
如果在汇编中单独描述一个指针(例如栈基指针,栈顶指针),他们并没有任何的类型,毕竟汇编语言根本没有类型.汇编需要做的仅仅是根据寄存器中存有的地址值去定位内存而已.
但是在C/C++中情况就变得不同了.高级语言与低级语言最大的不同之一就是引入了数据类型,对于一块特定大小的内存,我们不再认为他们仅仅是几字节的二进制数据,取而代之的是,我们对这块内存设定一个类型,让我们能够以这种类型来进行对应的,针对性的操作,而不是再一视同仁.
类型的引入不仅仅帮助我们指定了运算,并且更重要的是,它规定了大小.例如x86的int占用4字节,double占用8字节.这让我们在处理数据的时候,不再需要像以前那样按照一个字节/一个字/2个字等等的去处理,而是直接根据需要的类型,去自动选择需要的宽度.
那么C/C++中的指针为了"适应"这种变化,自然不能够仅仅地去指定一个值去表示一个地址,相应地,它必须有一个类型,用于确认以这个地址为起始,究竟有多长的内存空间被视为一个数据对象进行处理.
换句话说,C语言的指针是内存地址的一种高级抽象.
所以,关于"指针不是地址"这个说法,要对半地去看,你怎么说都是可以的,因为各有各的道理,总之要结合起来去思考.
指针和数组
指针和数组存在着很复杂的关系,不仅仅包含下面讨论的这一点知识.
数组指针
同理,既然C中指针能指向一般的内置类型,那么自定义的类型(例如数组)当然也应该可以指向,这就引入了数组指针,同理,声明一个指针数组也要写清楚具体的长度,这里实际上就是可以指向的数组的长度.
1 | int arr[10]; |
指针数组
指针数组实际上并没有什么单独拿出来的必要,因为指针变量(保存指针的变量)也是变量,只不过用来存储的值特殊了点而已.
那么,指针数组自然就是用来存储一系列的指针的数组了,没什么好说的.
1 | int* arr[10]; // arr为指针数组,数组中的元素都是指针 |
数组的首地址
实际上这个概念是比较模糊的,本人在这里给出一个逻辑:
数组的首地址的类型是指向这个数组的指针,也就是说,对这个类型的地址加1,结果是加了这个数组的长度.
例如:
1 |
|
这个程序输出的结果是40,也就是sizeof(a)的值.
其中,p中保存的就是数组的首地址,如果把初始化的值&a改为a,那么编译器会报一个警告(C语言中)甚至是报错(C++中).
而数组首元素的地址的类型就是指向数组元素类型的指针,我们看例子:
1 |
|
这个程序输出的结果是4,也就是sizeof(a[0])的值.
其中,p中保存的就是数组首元素的地址,如果把初始化的值&a[0]改为a,那么编译器会报一个警告(C语言中)甚至是报错(C++中).
我们注意到,第一个程序中,如果把给p的初始值从&a换成a,那么就会发生类型不匹配的问题.这里说的是C语言中数组标识符作为表达式时的一个特性:

实际上,在C/C++语言中,单独的数组名(也就是这个数组的标识符)作为表达式,其类型为指向数组元素的指针,而值和数组的首地址相等.所以,上图报错(C++中)称不能在初始化中将’int*'类型转换为’int (*)[10]'类型.
进一步,我们如果有int a[10];那么a+1实际上是一个指针运算,a+1的值显然,是a向后偏移了4个字节—也就是sizeof(int)*1,更准确的说,这里应该是sizeof(*a) * 4.
再例如我们有int a[10];和int offset=3;那么a+offset相对于a的值向后偏移了如下字节数:
sizeof(*a) * offset
指针和数组是否等价
数组就是指针?
说实话,在写这篇短文的时候,我也比较纠结,但是经过了不短时间的学习,并且恰巧看了《C++20高级编程》中相关的描述,我还是认为"数组就是指针"这句话一定程度上是对的.
一段有问题的代码
我们首先来看一段代码,这段代码实际上是有问题的,但是他没有报错!我们就是要说明这个问题:
1 |
|
该程序在Win11下使用gcc12.2编译成功为x64程序,运行结果为:
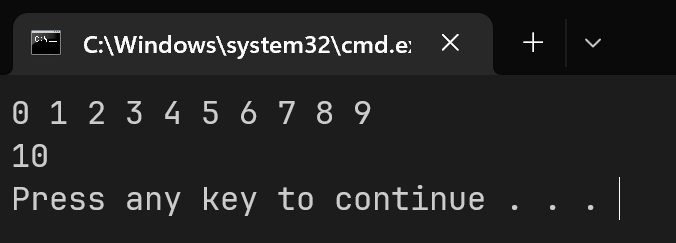
显然,程序中的第一个循环发生了溢出,实际上a只有0-9这个10个下标的元素,但是我们错误地对a[10]这个不存在的元素进行了赋值,然后会发现前面的int_before_a被覆盖了,也就是说,这里的所谓a[10]正是int_before_a.
有人可能会疑惑,明明int_before_a的声明位置在a的前面,为什么对a的访问"向后"溢出了,却能访问到前面的int_before_a?
实际上,在gcc实现中,函数内的各个局部变量默认从上向下依次压栈连续存储,我们又知道,栈从高地址向低地址开辟空间,也就是说,rbp(栈基寄存器)指向的函数栈帧的栈底在相对高地址处,而rsp(栈顶寄存器)指向的栈顶在低地址,每次rsp减小时,都意味着"压入"一个变量或寄存器的值等.
那么,首先从栈帧的高地址处先压入int_before_a这个局部变量,然后再继续压入a这个数组;而且,a的首元素是在靠近栈顶的一段;a的尾元素,也就是a[9],在靠近栈底的位置,就这个程序而言,a[9]的下面(指栈的底部)紧挨着就是int_before_a.
使用IDA反编译出来伪代码的结果如下:

再来看一下main函数的栈帧结果如下:
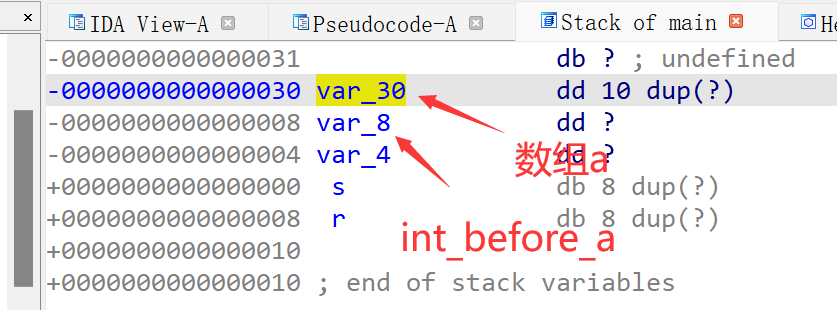
实际上,a[i]和*(a+i)完全等价,底层上,对数组进行下标运算确实是这样实现的,那么我们就可以理解,a[10]就被解释为*(a+10),那么a+10作为一个指针值,当然比a+9要大,意味着它指向更高的地址,这里实际上就恰好指到了int_before_a这个变量的位置,然后我们对其进行赋值,就发生了溢出.
数组就是指针
从语法层面,我们声明一个数组当然和声明一个指针完全不同,但是一旦编译器处理完毕,数组的各种行为就和指针一模一样,例如,下标运算被转换为对应等价的指针运算.
事实上,无论是C还是C++,数组都没有包含任何的大小信息(数组的长度)!这也是我们在C++中更推荐使用现代容器的一个原因!
如果数组能够相对于指针多出长度的信息,那么显然上面的溢出就没有那么容易出现.但是很遗憾,数组的下标运算被完全转换为指针运算,那么这时候,C编译器没有义务为你去检查你的操作是否合理,你至多只会收到段错误的异常而已.
如果你使用一些智能的IDE,你可能会反驳:我的软件明明给我提出了警告啊?
要知道,这是软件提供的智能服务,并不是C编译器自己的行为,软件可以找到可能潜在的问题,但是没有权利对这些问题进行绝对的禁止!只有真正的编译器才有权利去决定你的代码最终是否合法.
总而言之,所谓的"数组就是指针",指的是C语言数组的行为实际和对应的指针运算完全等价.
指针就是数组?
很显然,这句话是错误的!
什么时候指针等价于数组
只有当某个指针变量指向了某一块可以使用的,被分配好的,用于作为数组存储一系列值的数据块时,这个指针才和数组是等价的.
因为和一般的数组名作为标识符一样,它也特定标识了一段内存空间,我们便可以用这个指针变量进行数组访问.我们甚至可以对这个指针变量使用数组下标运算符!
例如:
1 |
|
我们在后面的代码中直接将p视作一个数组的标识来进行使用.当然,你仍然可以这样使用它:
1 |
|
什么时候指针不等价于数组
当指针仅仅指向了一个单一的变量(数据对象)时,它仅仅表现出一个普通的指针该有的行为,而我们若把它视作一个数组—那么显然很可能会出现像上面的溢出那样的问题.
当然,如果我们有下面的代码:
1 | int n=3; |
那么我们使用p来访问n,可以使用*p来完成,而且p[0]也是合法的,只是这种写法体现出来的风格十分可疑,并且没有带来任何的好处!
如何正确使用指针
另外我认为,使用指针的一个非常重要的思维就是,一定要搞清楚当前这个指针的类型,指针的行为与其类型息息相关.
例如很多人可能有一种错觉,就是在学习二维数组和指针的关系时,认为二级指针---例如int **和一维数组指针---例如int (*)[10]是一样的,毕竟他们都是在一维指针的基础上更上了一层,但实际上,二者的差别很大,如果你在学习阶段做了足够多的尝试和试错,你应该会有更加深刻的体会.
—WAHAHA 2023.10.1
 wechat
wechat alipay
alipay