分支界限法
概述
分支限界法是用于离散优化、组合优化以及数学优化问题的算法设计范式。其可以视为一种对可行解进行穷举的算法,但是在对某一分支进行检索之前会先算出该分支的上界或下界,如果界限不比目前最佳解更好,那么该分支就会被舍弃,从而节约了大量的时间。
分支定界算法非常依赖合适的上界或下界,如果无法找到合适的界限,该算法将会退化为穷举法。
和回溯法相同,分支界限法也是用状态空间树来进行组织。
与回溯法的区别:
- 求解目标:
回溯法的求解目标是找出解空间树中满足约束条件的所有解;而分支限界法则是找出满足约束条件的一个解,或是在满足约束条件的解中找出在某种意义下的最优解。 - 搜索方式:
回溯法以深度优先的方式搜索解空间树;而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树。
基本思想
以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。
在搜索过程中,对已处理的各结点根据限界函数估算目标函数的可能取值,从中选取使目标函数取得极值(极大/极小)的结点优先进行广度优先搜索,并不断调整搜索方向,以尽快找到解。
其中,限界函数常基于问题的目标函数,适用于求解最优化问题。
具体过程:
在遍历解空间(活结点列表)时,当到达某一结点(扩展结点)时,先判断该结点是否包含问题的解,如果包含,则产生其全部子节点,并将其中不可行解或导致次优解的子节点丢弃,然后将剩下的子节点加入活结点列表
此后,每次从活结点列表中取下一个结点作为当前的扩展结点,继续上述步骤,直到找到解或者列表为空为止。
两种分支界限法
队列式分支界限法
FIFO原则选取下一个扩展结点
优先队列式分支界限法
根据优先队列的优先级规则选取优先级最高的结点作为下一个扩展结点
算法流程
具体过程
- 确定合理的
限界函数,以及目标函数的[down,up] - 依次从活结点表中选取使目标函数的值取得极值的结点成为当前扩展结点(广搜)
- 依次搜索该结点的所有孩子结点,分别估算这些孩子结点的目标函数的可能取值
- 丢弃目标函数可能取得的值超出目标函数的界对应的子结点,因为其不会产生更好的解
- 将其他结点加入活结点列表
- 重复上述步骤,直到找到解
叶子结点与解
随着遍历,活结点表中所估算的目标函数的界越来越接近问题的最优解,广搜过程有如下状态:
- 搜索到叶子:得到一个解,如果其目标函数值是活结点列表中的极值,则它就是最优解
- 否则,根据该节点调整目标函数的上/下界
- 更新队列(活结点表):将超出目标函数界的结点丢弃
- 然后从活结点表中选取使目标函数取得极值的结点继续进行扩展
01背包问题的分支界限法
界限条件
判断将某个物品i放入背包是否会超重,如果不超重,则可以对该”选择将物品i放入的结点“继续搜索,否则丢弃该结点
另一方面,如果选择不放入物品i,则自然不会超重,可以继续对该”选择不将物品i放入的结点“继续搜索
上界估算优化
我们维护每个结点对应的上界,这个上界代表着,以该节点做出的决策继续,理想情况下能获得的最大价值。
为了计算这个上界,对于01背包,显然可以计算每个物品的“性价比”,即单位重量的价值。
之后,每次选取都优先选择性价比最高的物品,并更新上界,然后,在搜索活结点列表时,每次取出上界最高的结点进行搜索,即使用优先队列。
搜索过程
- 每次都从优先队列中找到当前上限值最大的结点,遍历并生成该结点的子结点(左孩子放入该物品,右孩子不放入该物品),如果不满足界限条件(超重)则丢弃。
- 将子结点入队,准备下一次遍历。
- 如果弹出的结点是叶子,那么该结点就是最优解。
优先队列法求解最大化问题的一般步骤
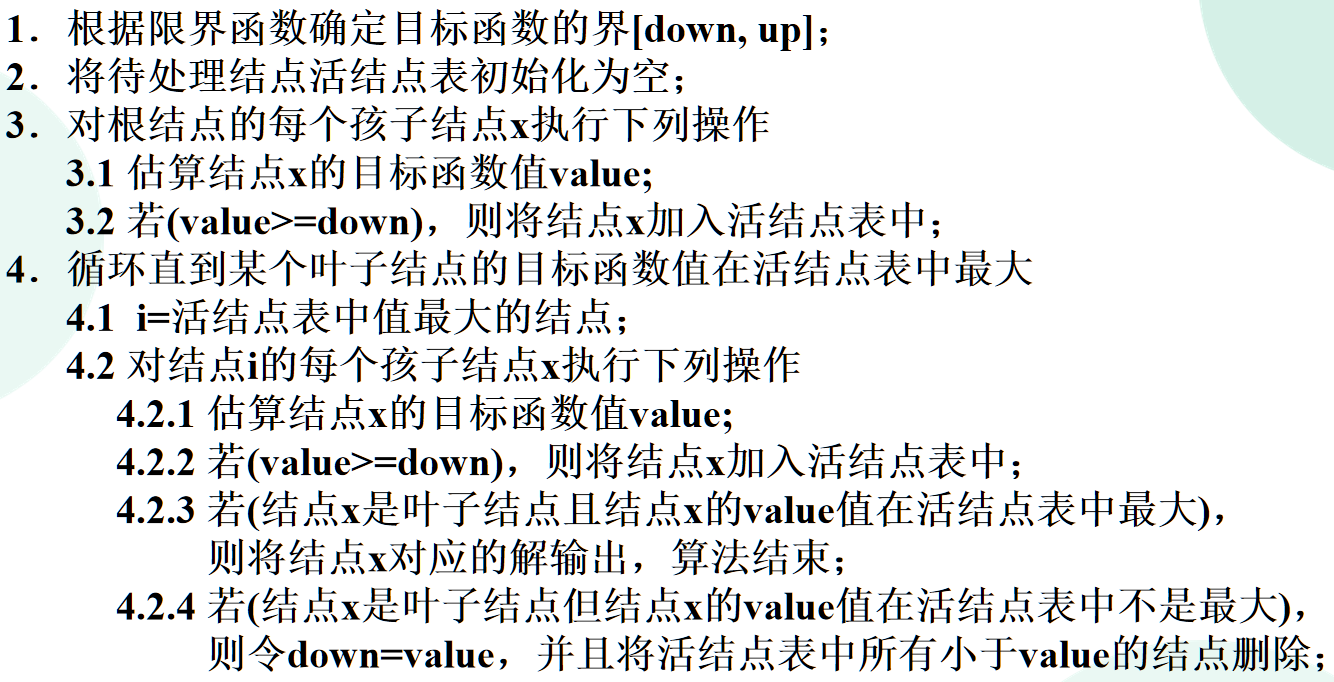

其中,确定最优解的分量可以有2种方法:
- 保存迭代路径
- 回溯到根节点,以获取分量
分支界限法的性能
分支限界法和回溯法实际上都属于穷举法,遍历具有指数阶个结点的解空间树,在最坏情况下,时间复杂性肯定为指数阶。
与回溯法不同的是,分支限界法首先扩展解空间树中的上层结点,并采用限界函数,有利于实行大范围剪枝,同时,根据限界函数不断调整搜索方向,选择最有可能取得最优解的子树优先进行搜索。
分支界限法使用了一些特殊的方法来提高搜索效率,当然这也使得算法设计变得更为复杂,具体体现如下:
- 限界函数:一个更好的限界函数通常需要花费更多的时间计算相应的目标函数值,而且对于具体的问题实例,通常需要进行大量实验,才能确定一个好的限界函数;
- 算法设计较为复杂:为了从叶子结点求出对应最优解的各分量,需保存该结点到根结点的路径,或者在搜索过程中构建经过的树结构;
- 需要较大的存储空间:算法要维护一个待处理结点(活结点)表,并且需要在活结点表中快速查找取得极值的结点,等等。在最坏情况下,需要的空间复杂性是指数阶。
队列式分支界限法
首先检测当前扩展结点的左儿子结点是否为可行结点,如果是则将其加入到活结点队列中;
然后将其右儿子结点加入到活结点队列中,因为右儿子结点一定是可行结点;
2个儿子结点都产生后,当前扩展结点被舍弃。
活结点队列中的队首元素被取出作为当前扩展结点;
由于队列中每一层结点之后都有一个尾部标记-1,故在取队首元素时,活结点队列一定不空;
当取出的元素是-1时,再判断当前队列是否为空。如果队列非空,则将尾部标记-1加入活结点队列,算法开始处理下一层的活结点。
注:本文参考自课程ppt
 wechat
wechat alipay
alipay