迪杰斯特拉算法概述
单源最短路径问题,即求出一个赋权图的某一点s到其他任意点的最短路径.Dijkstra算法即为解决该问题的一种算法.该算法基于贪心策略,每次寻找一个距离源点s最近的点v(未被更新的),使用以v为起点的所有出边去进行松弛操作,逐步缩小各点到s的距离,直到所有的点都被选取完.
需要注意的是,该算法无法处理带有负权边的图,不过可以处理带环图.而且在使用堆优化,并使用邻接表进行存图的情况下,Dijkstra算法往往有着很高的效率.
算法描述
算法过程
首先确定起点(即源点s),将所有点与起点的距离初始化为无穷大,一般存储在一个dis[]数组中,s到自己的距离(即dis[s])设置为0,此时dis[]即为初始状态,后续操作都是在维护这个数组.
设置一个标记数组vis[],全部初始化为0,即一开始均未访问过.然后将vis[s]设置为1,即一开始从s开始访问.
不断从vis[]数组中寻找未被访问过的点u,同时保证每次寻找到的u满足dis[u]为未被访问过的点中最小的那一个.找到后将vis[u]设置为1,即代表该点已经被访问,亦即已经找到最短路径.
遍历第3步中找到的一个点u的所有出边<u,v,w>(以u为起点,v为终点,权值为w的边),尝试使用此边缩短dis[v],即如果有dis[v]>dis[u]+w,则更新dis[v]=dis[u]+w.
重复第3,4步,直到vis[]数组全部置为1(即所有的点遍历完成).此时dis[i]即为s到i的最短路径.
过程描述
dis[]数组即为最终的结果,其中任意一元素dis[i]代表从s到i的最短路径长度.
vis[]数组用于标记,其中任意一元素vis[i]为0代表该点还未被访问;为1代表已经访问.
换句话说,vis[]数组将点集V划分为两个集合Set和UnSet,Set代表已经访问过的点,UnSet代表未访问过的点,每访问一个点i就将其从UnSet中放到Set中,直到UnSet为空(或者Set内点数为n,即Set满),此时代表着算法结束.
第4步的缩短操作,这步操作即为所谓的松弛,不断地拉近各点到起点距离的操作.
对每一个点,尝试使用其所有出边进行松弛,直到所有的点(从源点可达的点)访问完,所有的边也就访问完.此时,dis[]数组中就是最终的结果.
算法分析
思想分析
Dijkstra算法和SPFA等算法在操作上十分相似,但是思想截然不同,将其他算法学会后会有更加深刻的认识.
Dijkstra算法基于贪心的思想,具体体现在每次选取dis[u]最小的点u,即当前距离点s最近的,未访问过的点.在该点的基础上去更新其他点.
另外这一个重要的选取方法意味着:只要一个点u一旦被访问过,则其dis[u]一定已经是是最小的,即以后一定不会被再次更新,因为每次选择的点都是最近的点.可以这样简单证明:
设有一点u,其vis[u]==1,假设其dis[u]不是最小的.
那么设在u被访问之后有一点v被访问到.并且点v有一条出边<v,u,w>指向u.
因为在选取u时,u和v均未被访问,则根据选择方法有dis[u]<dis[v].
此时遍历点v的出边到<v,u,w>,即检查dis[u]>dis[v]+w是否成立,
由于dis[u]<dis[v],且由Dijkstra算法大前提图无负权边得w>0,所以dis[u]<dis[v]+w,进而得dis[u]>dis[v]+w显然不成立.
这与假设不符,因此dis[u]是最小的.
也就是说,dis[u]不会被再次更新.即在此之前dis[u]已经为s到u的最短路径长度.
证毕.
事实上,点的选取策略(贪心)某种程度上是为了给松弛操作使用哪些边提供了一个依据.学习了SPFA算法(基于动态规划,体现有BFS的思想)后可能会有更深刻的体会.
换句话说,主观上讲,贪心就是此算法的"搜索依据".而BFS是SPFA的"搜索依据".
算法局限
Dijkstra算法不能有效处理带负权的图,这是因为一旦存在负权,那就有可能在后面通过一个次优点的一条负权的出边,缩短之前某一次松弛用的点v的dis[v],使得路径之和进一步缩小,这就导致了错误.
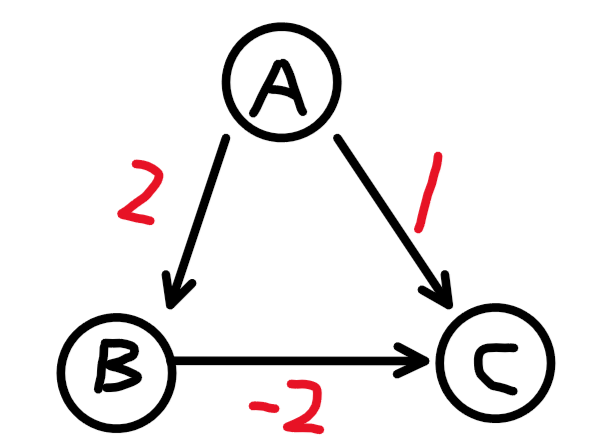
举一个简单的例子:
访问到A时,选择最优点C(A->B为2,A->C为1,后者更短),将C标记,之后意味着C不能再被更新了.
但是显然,A->B->C这条路径计算出的A到C的路径长度为0,显然比原来的1更短,发生错误.
所以该算法在有负权边的图中无法使用.
朴素写法时间复杂度
之所以说朴素写法是因为该算法后续还有一个十分重要的堆优化可以大幅提高效率.
对于一个n个顶点,m条边的图:
显然,大循环要将所有的n个点进行访问一次,每次寻找最小dis的点需要一个O(n)的循环.另外还需要访问所有的边一遍(尽管是在大循环中,并且基于寻找的最小dis的点),需要O(m).
所以时间复杂度为O(n^2+m),当n十分大,m相对较小时不占优势.
(但是鉴于此算法的贪心策略,后续可以有一种堆优化.)
朴素写法
前置知识:请先去学会邻接表或链式前向星.邻接矩阵在此算法中不占优势,特别是当图十分稀疏的时候更加明显.
本代码示例为纯C语言,采用链式前向星存图.简单又高效,OIer的首选!好东西!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #include <stdio.h> #include <stdlib.h> typedef struct { int to, dis, next; } Edge; typedef struct { Edge *edge; int *head; int cnt; int n, m; int start; } Graph; void add_edge (Graph *graph, int from, int to, int w) { graph->edge[++graph->cnt].to = to; graph->edge[graph->cnt].dis = w; graph->edge[graph->cnt].next = graph->head[from]; graph->head[from] = graph->cnt; } void init_graph (Graph *graph) { scanf ("%d%d" , &graph->n, &graph->m); scanf ("%d" , &graph->start); graph->head = (int *) malloc (sizeof (int ) * (graph->n + 1 )); graph->edge = (Edge *) malloc (sizeof (Edge) * (graph->m + 1 )); graph->cnt = 0 ; for (int i = 1 ; i <= graph->n; i++) graph->head[i] = 0 ; for (int i = 0 ; i < graph->m; ++i) { int from, to, w; scanf ("%d%d%d" , &from, &to, &w); add_edge(graph, from, to, w); } } int *dijkstra (Graph *graph) { int start; int *vis = (int *) malloc (sizeof (int ) * (graph->n + 1 )); int *dis = (int *) malloc (sizeof (int ) * (graph->n + 1 )); for (int i = 1 ; i <= graph->n; i++) { dis[i] = 0x7FFFFFFF ; vis[i] = 0 ; } start = graph->start; dis[start] = 0 ; for (int j = 0 ; j < graph->n; ++j) { int min = 0x7FFFFFFF , min_index = -1 ; for (int i = 1 ; i <= graph->n; ++i) { if (dis[i] < min && !vis[i]) { min = dis[i]; min_index = i; } } if (min_index == -1 ) break ; vis[min_index] = 1 ; for (int i = graph->head[min_index]; i != 0 ; i = graph->edge[i].next) { if (dis[graph->edge[i].to] > dis[min_index] + graph->edge[i].dis) dis[graph->edge[i].to] = dis[min_index] + graph->edge[i].dis; } } free (vis); return dis; } int main () { Graph graph; init_graph(&graph); int *dis = NULL ; dis = dijkstra(&graph); for (int i = 1 ; i <= graph.n; i++) printf ("%d " , dis[i]); free (graph.head); free (graph.edge); free (dis); return 0 ; }
代码分析全在注释里了…
(二叉)堆优化写法
本质上就是要优化那个贪心策略的内循环,寻找dis最小的点O(n)实在太慢了,通过构建一个二叉堆(最小堆)来优化.
通过堆优化可以将时间复杂度降低到O((n+m)*log(n)),具体分析略,掌握二叉堆的时间复杂度分析会有帮助.
本代码使用C++编写,二叉堆使用C++ STL的priority_queue来实现(实际上仍然是利用二叉堆优化).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <iostream> #include <algorithm> #include <queue> #include <vector> #include <cstdio> #include <cstring> #define INF 0x7FFFFFFF using namespace std ; int cnt, n, m, s, head[100003 ], dis[100003 ];bool vis[100003 ];struct EDGE { int to, dis, next; } edge[500003 ]; typedef pair <int , int > p;priority_queue <p, vector <p>, greater<p> > q;void add_edge () { int from; cin >> from; cin >> edge[++cnt].to; cin >> edge[cnt].dis; edge[cnt].next = head[from]; head[from] = cnt; } void init () { cin >> n >> m >> s; for (int i = 0 ; i < m; ++i) add_edge(); for (int i = 1 ; i <= n; ++i) dis[i] = INF; } void dijkstra () { dis[s] = 0 ; q.push(p(0 , s)); while (!q.empty()) { p node = q.top(); q.pop(); int v = node.second; if (vis[v])continue ; vis[v] = true ; for (int i = head[v]; i; i = edge[i].next) { if (dis[edge[i].to] > edge[i].dis + node.first) { dis[edge[i].to] = edge[i].dis + node.first; q.push(p(dis[edge[i].to], edge[i].to)); } } } } void print () { for (int i = 1 ; i <= n; ++i) cout << dis[i] << " " ; } int main () { init(); dijkstra(); print(); return 0 ; }
思想上很简单,相当于使用前面说的UnSet集合构建一个二叉堆(最小堆),堆排序依据为堆中每个元素对应的顶点i的dis[i]大小,这样每次获取最小dis的点就是O(1),并且从堆中pop这个点是O(log(n)).
二者结合起来,总的时间复杂度显然比原先整个遍历的O(n)要小得多,这样便有了效率提升.
 wechat
wechat alipay
alipay